OFFENSIVE SECURITY ENGINEERING PLATFORM
Offensive security for the teams that are 100x outnumbered
Replace legacy scanners and manual offensive security processes with AI agents that discover, test, and remediate directly in your engineering workflows.

Trusted by 2000+ security teams worldwide

Our Products
Attack Surface Management

Discover and validate exposure
of modern applications, APIs, and infrastructure
from code to cloud
from code to cloud
Business-logic-
aware DAST

Replace legacy DAST with
business-logic-aware testing that improves over time and helps your team remediate real,
exploitable vulnerabilities.
AI Pentesting

Replace manual pentest and bug
bounty programs with a solution that scales.
Find and fix complex web security issues while reducing costs.
Find and fix complex web security issues while reducing costs.




Stop playing whack-a-mole
Security isn't a checklist. It's
a continuous program.

1.
Discover (ASM)
2.
TEST (dast)
3.
Validate (AI Pentest)
4.
Remediate
5.
AUTOMATE
6.
Comply
Attack Surface Management
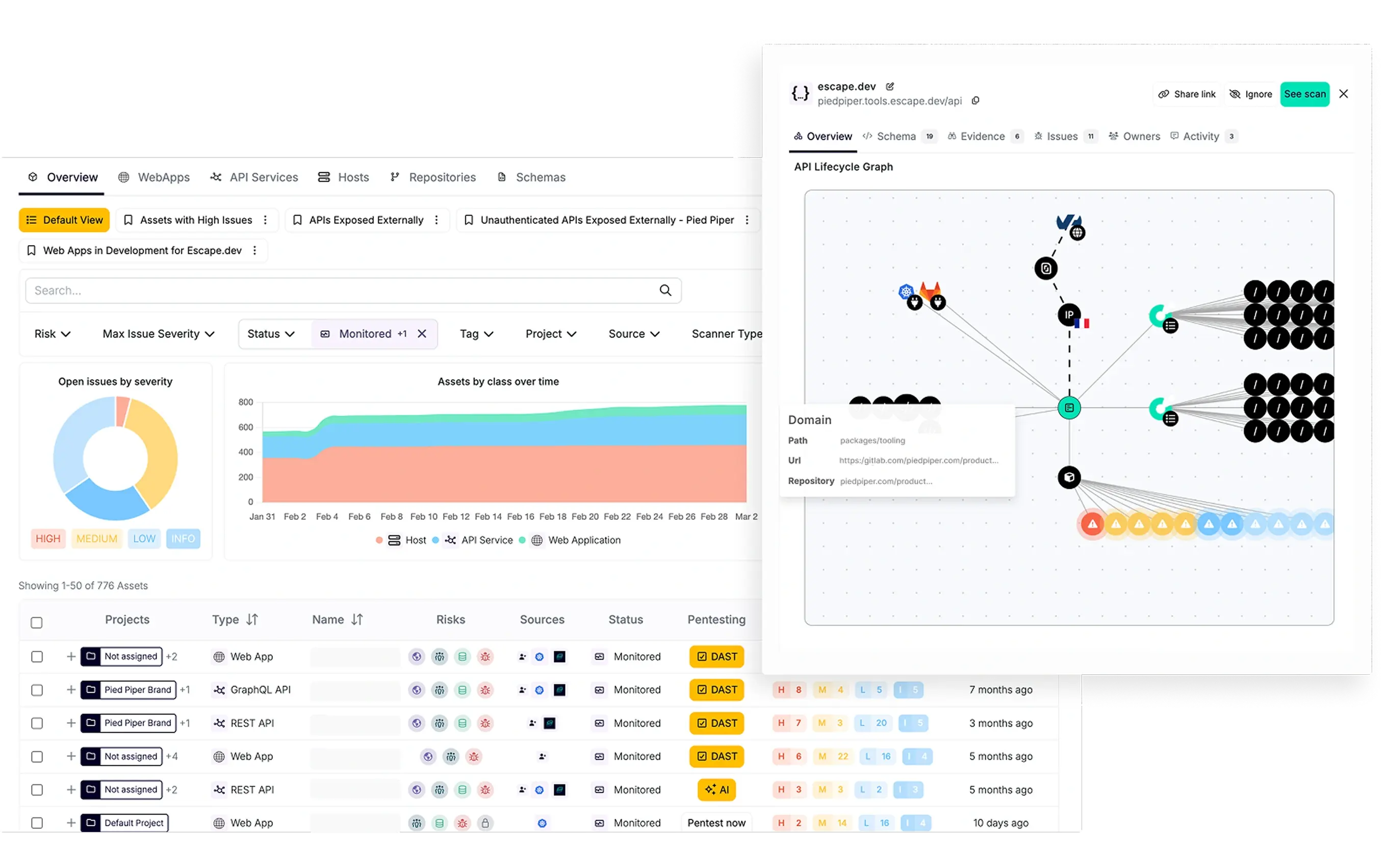
229% detection increase
DISCOVER EVERY API, EVERY APP, IN REAL
TIME
Assets flow directly to Wiz, so your risk platform
gets better context
Findings route directly to the teams that own
assets, with asset context already attached
We discover APIs and SPAs, not just DNS and ports,
both internal and external
1
.
Discover (ASM)
Business-Logic-Aware DAST
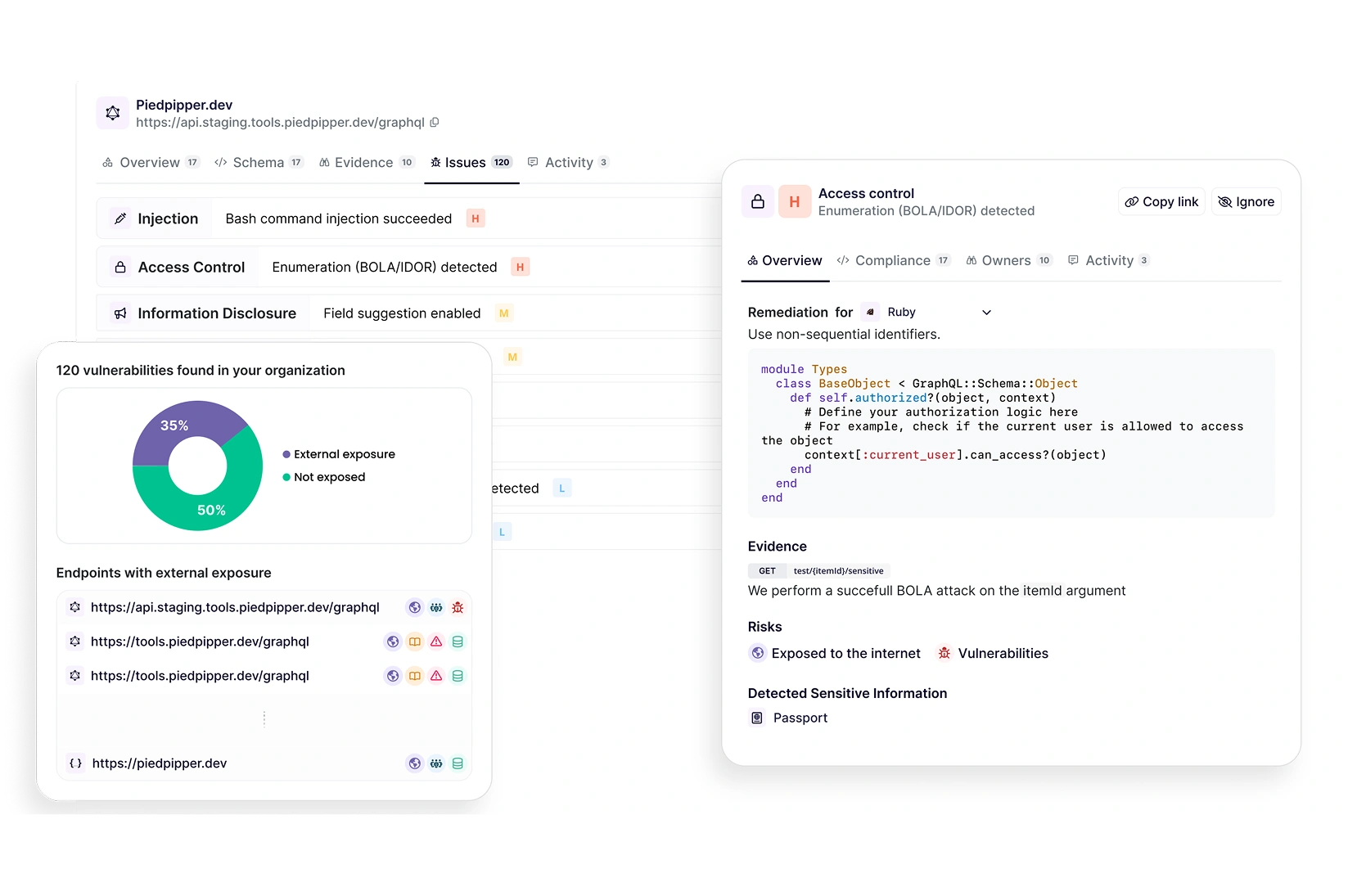
≤4% FP rate
TEST EVERY RELEASE AT THE BUSINESS LOGIC
LEVEL
Business logic testing: We test workflows, access
control, and multi-step processes, not just payloads
Built for modern auth: OAuth, SSO, multi-tenant
Developer-friendly context: Screenshots,
exploration graphs, and detailed tailored remediation steps engineers trust
Integration with Wiz for unified risk view
Integration with Wiz for unified risk view
2
.
TEST (dast)
AI Pentesting
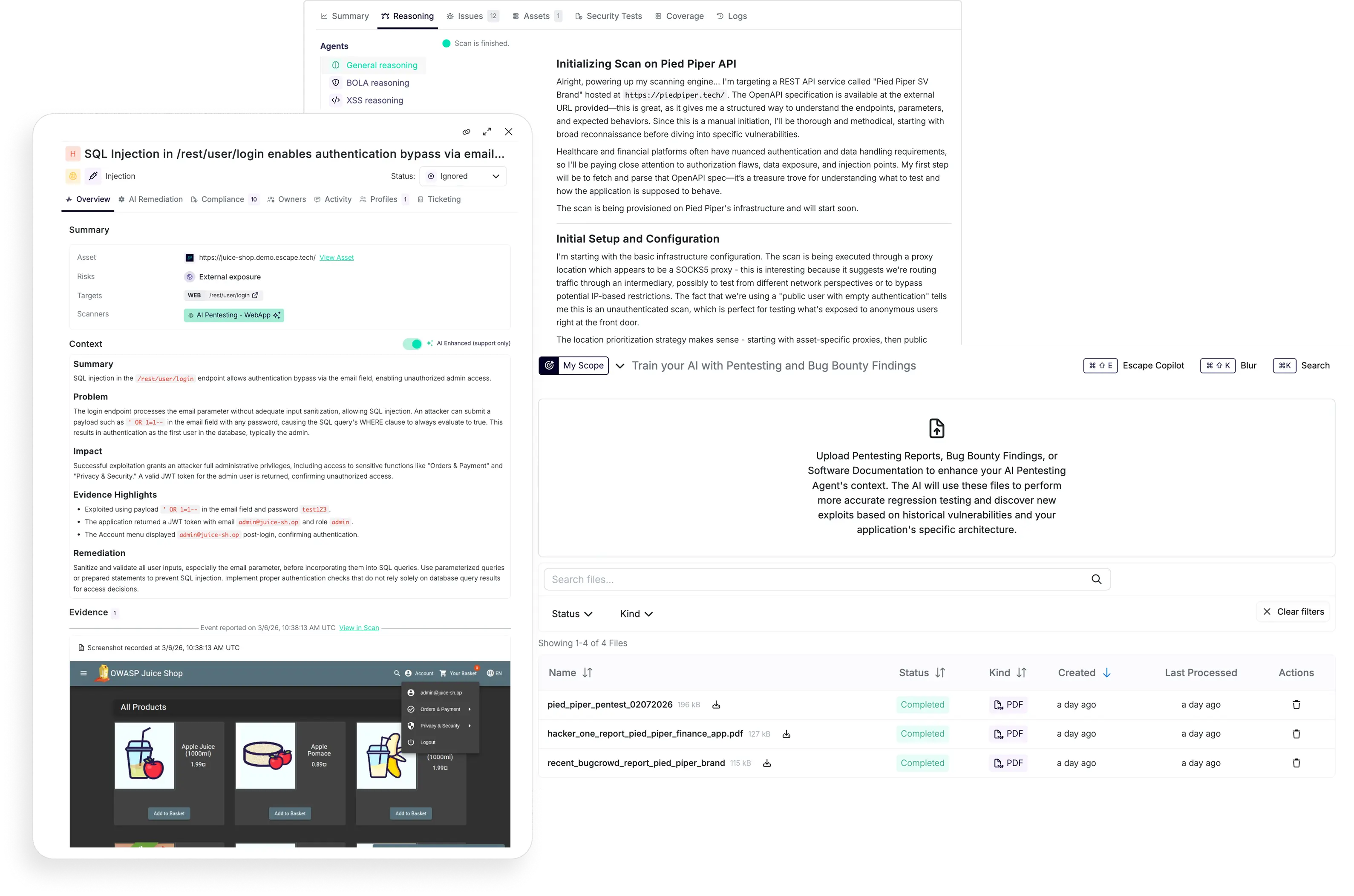
5 days turn into 5 hours
PROVE EXPLOITABILITY AT SCALE
Agentic attack reasoning powered by Graph context
: Finds complex multi-step attack chains
Proof of exploitability: Screenshots, execution
logs, and attack path validation
Regression testing: Ingest bug bounty findings; AI
reproduces them to prevent recurrence
3
.
Validate (AI Pentest)
AI-powered Remediation
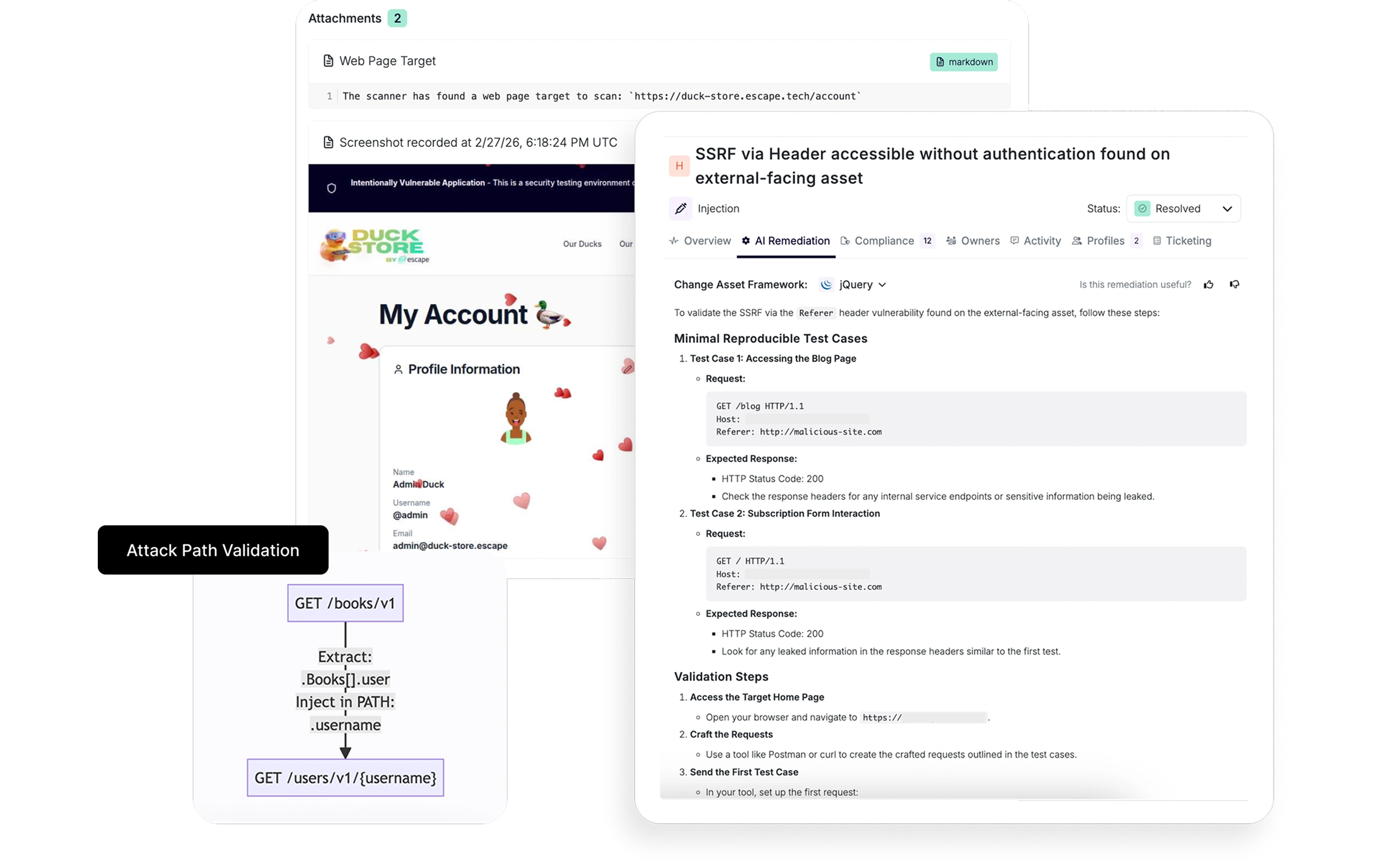
<1 min code snippet generation
DELIVER AI-ASSISTED REMEDIATIONS TO
ENGINEERING
Not "use input validation." Real code
suggestions tailored to React, Django, Spring Boot, whatever they are using.
Visual Proof: Screenshots & graphs showing the
exploit path. Engineers see how it's vulnerable, not just that it's vulnerable.
Native integrations with AI-assisted IDEs like
Cursor, Claude Code and Gemini to automate remediation end-to-end, in real time, without efforts
4
.
Remediate
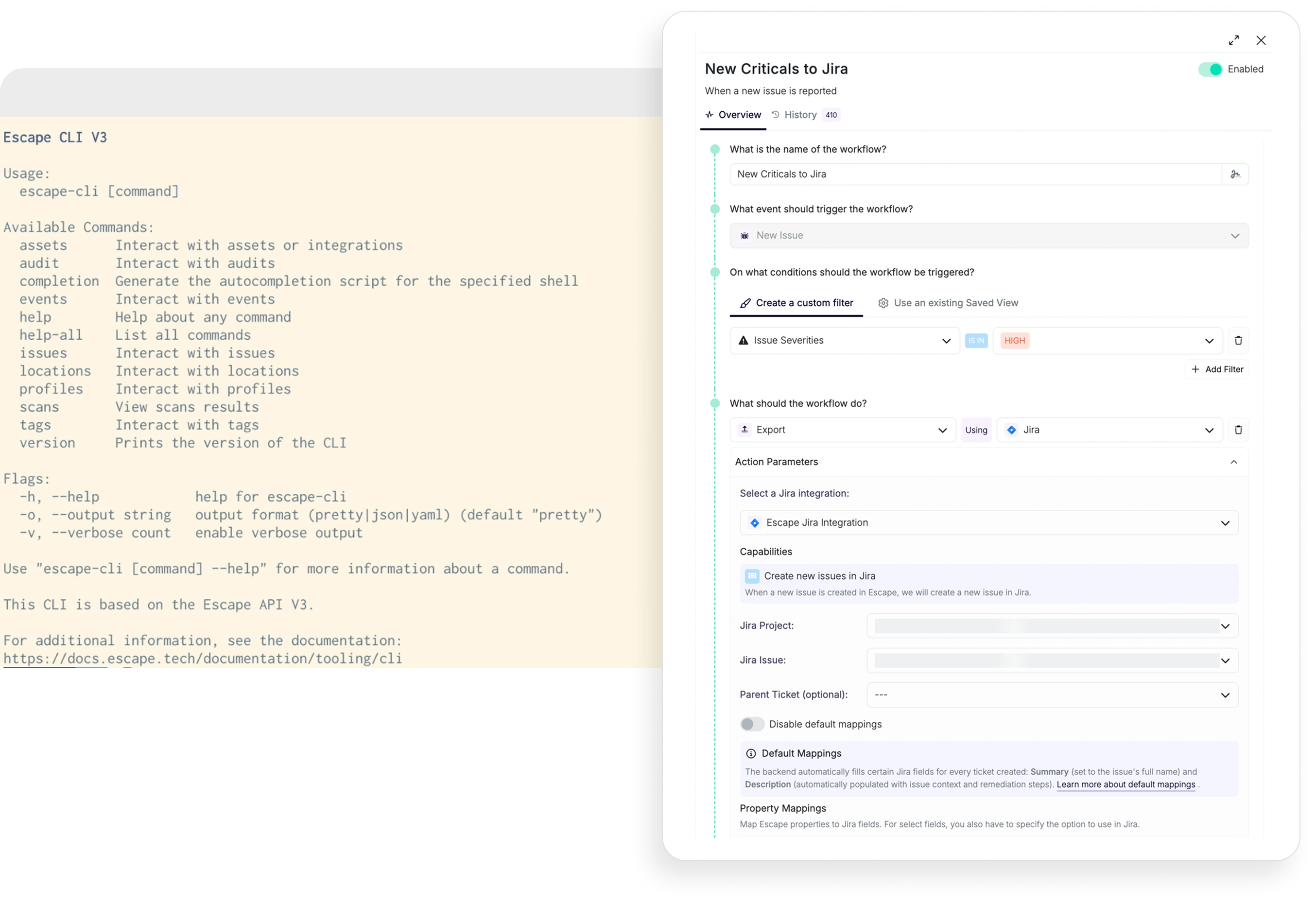
Automate your security program, not just your SCANS
<15 min setup
AUTOMATE OFFENSIVE SECURITY END-TO-END
Fully programmable: Public API, CLI, and MCP
Server. If the platform can do it, your scripts can too.
Event-based workflows to triage, route, and
escalate findings. Define your policy once, the platform enforces it.
Trigger scans on every push. Security gates run in
your CI/CD without your team in the loop.
5
.
AUTOMATE
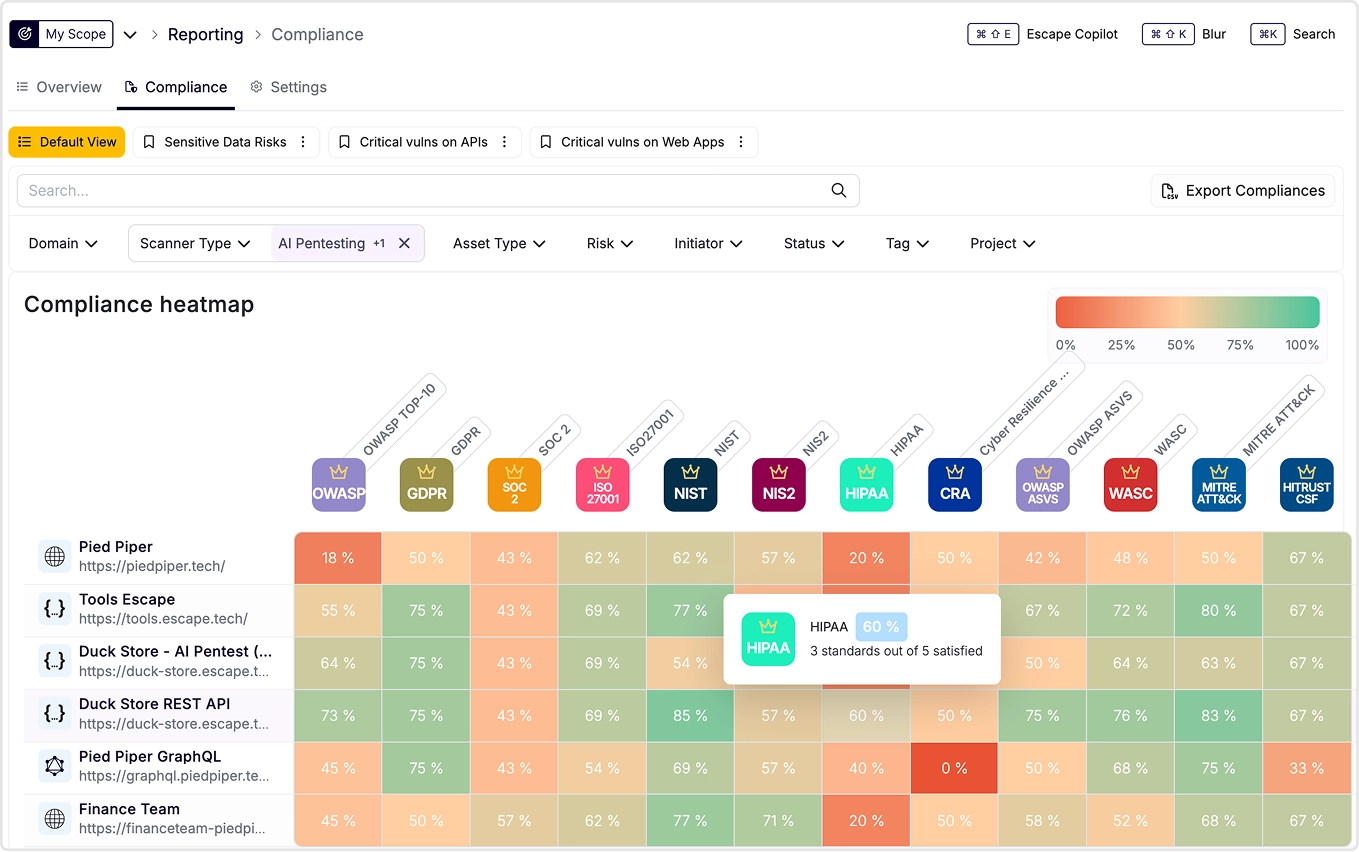
Compliance that satisfies auditors
<1 min report generation
GET COMPLIANCE FOR EVERY FRAMEWORK, ON
EVERY ASSET
Continuous compliance validation, not
point-in-time snapshots
Audit-ready reports with proof of testing in one
click
PCI-DSS, HIPAA, CRA, SOC 2, ISO 27001 and 20+
other frameworks natively supported
6
.
Comply
Real impact, straight from the field
Mission reports speak for themselves
12
saved per security engineer per month
"Escape integrated seamleassly with our
tooling and quickly secured our GraphQL endpoints."

"We saw Escape DAST being a lot smarter,
understanding what’s happening, where it is located."

“The time-to-value ratio is just 100% there. While most
DAST scanners on the market are built for Web Applications, Escape DAST is purpose-built to
protect APIs on top of Web Applications.”

Michael
Bourgault
Sr.Security Architect
Sr.Security Architect

50%
applicaiton risk reduction within first weeks
“We knew that Escape is really powerful on the dynamic
scanning and making sure that we have complete coverage, looking at business challenges, and
making sure that we map our API attack surface to those business challenges.”

Seth
Kirschner
Sr.AppSec Manager
Sr.AppSec Manager

393% ROI
of a security testing process for a Head of AppSec & Offensive
security team
"Escape's IDOR scanning and multi-tenant
capabilities set it apart from other security testing solutions and allow us to test multiple
scenarios. AI-based authentication and project-scoped permissions significantly reduce the
onboarding time and efforts."

Daniel Ilies,
IT Security Engineer
IT Security Engineer

“Escape addressed a gap in our AppSec program
which couldn't be addressed with our current AppSec tool”
5h
Replacement of manual pentesting process that previously took five days
“You can ultimately create custom scanning
rules for every technology that you're scanning”

3900%
Coverage improvement over legacy solutions
Security research powers everything we do
Read all the resources
In their own words. They’re now in full control.


Built-in house by Security and AI
Research teams
Escape acts as Business Enabler and fits seamlessly into your ecosystem
modern frameworks
cloud environments
security tools
developer tools
Pyhton
Don’t let your vulnerabilities escape.
Ready to multiply your force, not just noise?
Book a demo
Book a demo