Escape's DAST proprietary Business Logic Security Testing algorithm: what makes it innovative


Testing APIs for Business Logic vulnerabilities is hard. Actually, this is a mission that old-school DAST solutions like ZAP (formerly OWASP ZAP) cannot handle.
I'm Antoine Carossio, passionate about Computer Science for more than 15 years now and cofounder & CTO of Escape. With my team, we've spent 3 years building a proprietary algorithm capable of finding Business Logic vulnerabilities in all API types, especially in the most recent ones like REST & GraphQL.
However, simply stating its existence isn't often enough for the security community.
From security engineers, we constantly hear the same question: How does it work? Are you yet another wrapper of ZAP?
That's why in this popularization article, I'm proud to explain to the world how we created the state-of-the-art Business Logic Security Testing algorithm and what makes it truly innovative, so you or your peers don't have to ask this question any longer!
The real challenge: generating legitimate traffic on APIs
The heart of Escape is inspired by the concept of Feedback-Driven Semantic API Exploration (FDSAE), a Reinforcement Learning algorithm concept introduced by Marina Polishuck, Researcher @ Microsoft (REST-ler)
The primary goal of Feedback-Driven Semantic API Exploration (FDSAE) is, first and foremost, to create an algorithm able to generate legitimate sequences of requests that respect the business logic of APIs in a pure black box manner (no access to traffic or code). At that point we do not even talk about security, but about generating traffic.
Microsoft REST-ler is a fascinating piece of research. As a result, Marina shows how feedback-driven semantic API exploration drastically increases the API coverage and vulnerability findings compared to a mere brute force approach.
Nonetheless, the limitations of Marina's approach:
1. Not suited for CI/CD usage because too long
2. Only compatible with REST APIs
3. Since then, time has passed, and significant advancements have occurred, including the evolution of artificial intelligence.
This is why at Escape we decided to start again from scratch to build a revolutionary AI-powered engine that generates traffic, replicating application behavior within the context of business logic. It is built by design for all kinds of modern APIs, including REST and GraphQL, and does not require any traffic.
How does it work?
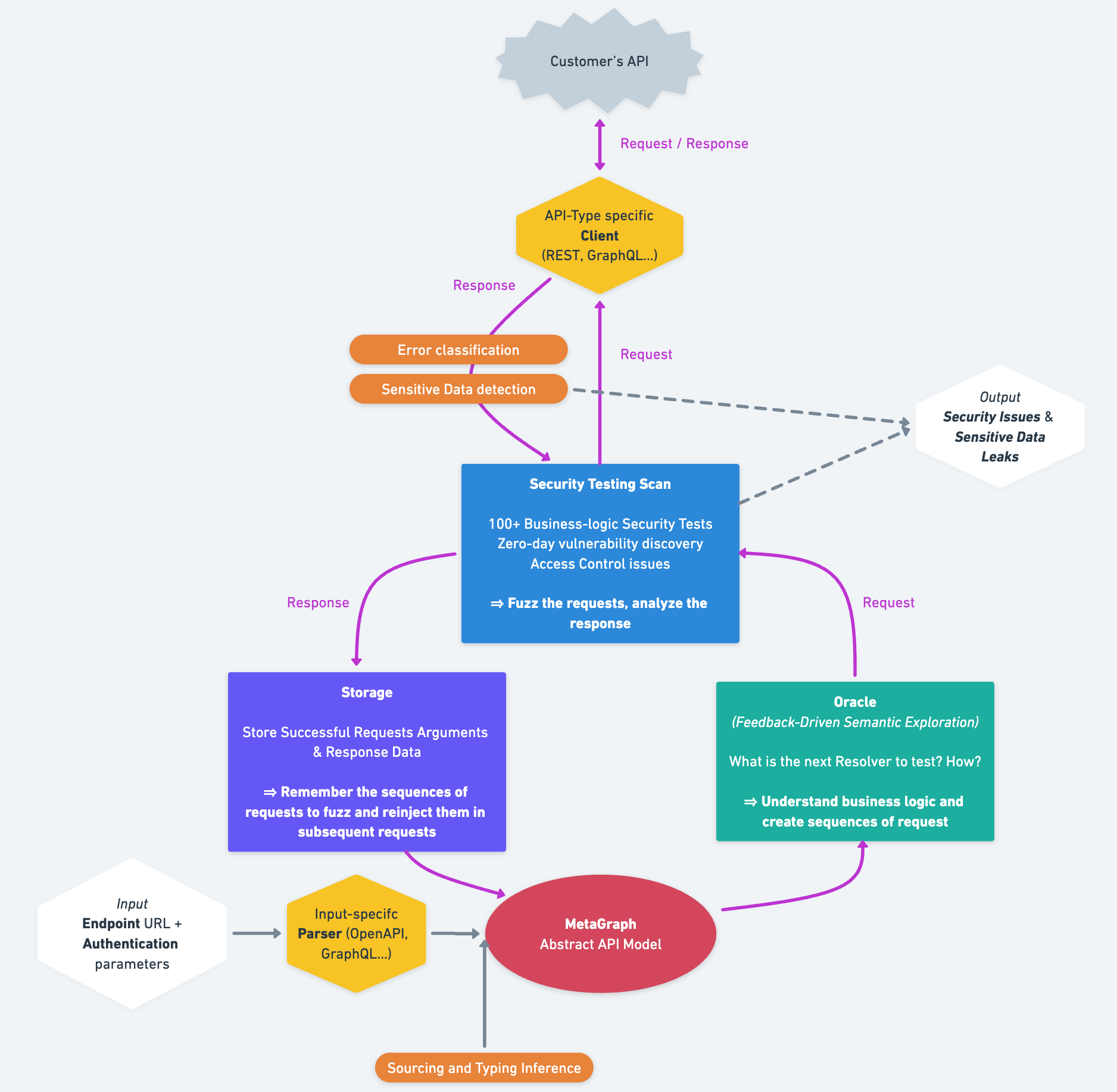
The MetaGraph: A unified model to rule all API standards
Escape takes as input an API Schema, that can either be automatically generated by Escape from the outside (this will be the topic of another article dedicated to describing how Escape's API Discovery and Inventory works), automatically generated by the API Backend Framework, or manually maintained by developers (Swagger v2, OpenAPI v3, Postman Collection, Insomnia Collection, WP-JSON, GraphQL Introspection, GraphQL Schema, etc.).
At that point, whatever the underlying technology or input, the schema is parsed and converted to a representation that is fully agonistic of the underlying API technology, that’s what we call the MetaGraph. We noticed that any API could, in fact, be represented in a Graph structure.
For the sake of simplicity, we are going to present a simplified version of this MetaGraph on a very simple REST API representing the following structure. Although the basic concepts are fully respected, the actual MetaGraph structure is, in fact, more granular than the one presented in this article and could be the topic of a more scientific article.
Let’s consider the following dummy API. Escape uses different hyperparameters depending on whether the database is already seeded or empty. Let’s take the assumption that the database behind this API is empty in our case.
Our API contains 1 Resource:
User, with 2 Fields:ssn: stringemail: string
and 3 Resolvers:
POST /user- 2 params in body
email: stringssn: string
- no return value
- 2 params in body
GET /users- no param
- returns a list of
User[]
GET /user/{id}→User- 1 param in path:
id: string
- 1 param in path:
The MetaGraph is a bipartite Graph with 2 kinds of nodes:
1. All the Resolvers are accessible in the API, here there are 3
2. All the Resources: here 1 User
Each resolver is weighted by a combination of:
- The probability of success that sending an actual request on this resolver with the information leads to a successful request that passes the validation layer
- The potential quantity of information returned by a resolver if sent right now.
- The cycle of creation and access to objects present in the database, which is similar to
CRUDfor REST APIs.
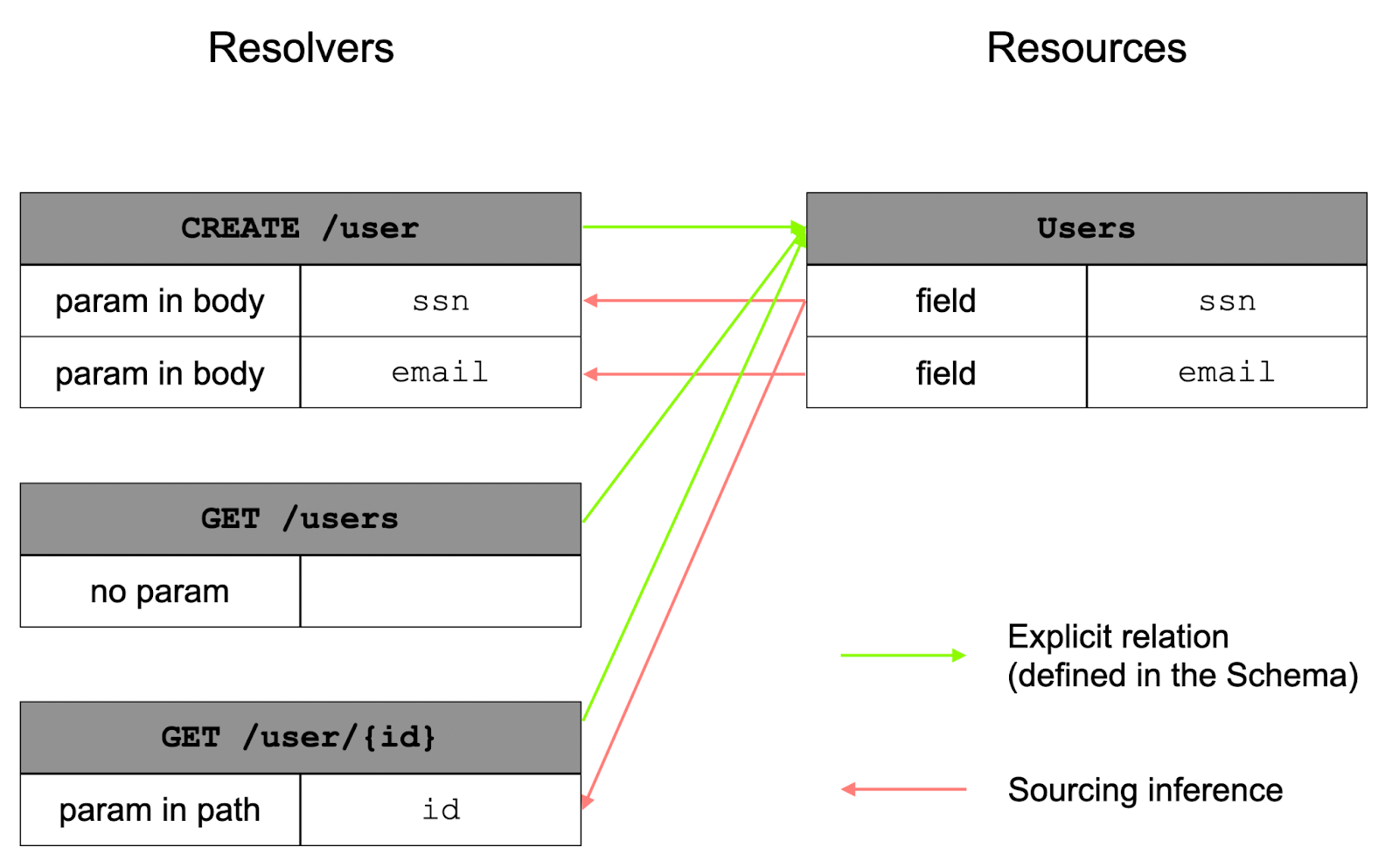
Sourcing inference
At this stage, we have a Graph that contains weighted nodes, but still no edges. The Graph is also directed. And there are 2 types of edges:
- Edges from
ResolverstoResources.- These are immediately given by the specification. For example, in our case, the 2
GETresolvers are connected to theuserobject.
- These are immediately given by the specification. For example, in our case, the 2
- And edges from
ResourcestoResolvers.- This is information that is not carried by the schema. Yet, in our case, the
GET /users/{id}resolver takes anidas a param in path. This ID actually comes from theuserobject. This relationship is not explicitly stated anywhere, so it must be inferred. This is what we have called parameter sourcing. In this case, we are out of luck: the API was designed in such a way that thessnfield of theuserobject is actually documented as being theidparameter of theGET /users/{id}resolver. The semantics are different: how to connectssnandid? The field could very well have been calledidas well. Here, we use a Machine Learning model applied to NLP capable of inferring these relationships in their context, what we have called sourcing inference.
- This is information that is not carried by the schema. Yet, in our case, the
Strong typing inference
Sourcing inference is actually completed with a second machine learning algorithm we named typing inference. Indeed, to send requests that are logical and adhere to the API's business logic, we must ensure the data we send is meaningful. It would be pointless to send a simple string to the email object when it is expected to be an email address or a simple id to the ssn field when it is in fact a social security number. Therefore, our algorithm supports over 800 different specific data types and includes a Resolver Parameter <> Resource Field classification algorithm, which operates in conjunction with sourcing inference. This algorithm considers the entire context of the parameter/field to assign it the most accurate data type possible.
To continue with our previous example, the GET /user/{id} query takes a param in path id type string and returns a User object that contains an email field and a ssn field, both in string type.
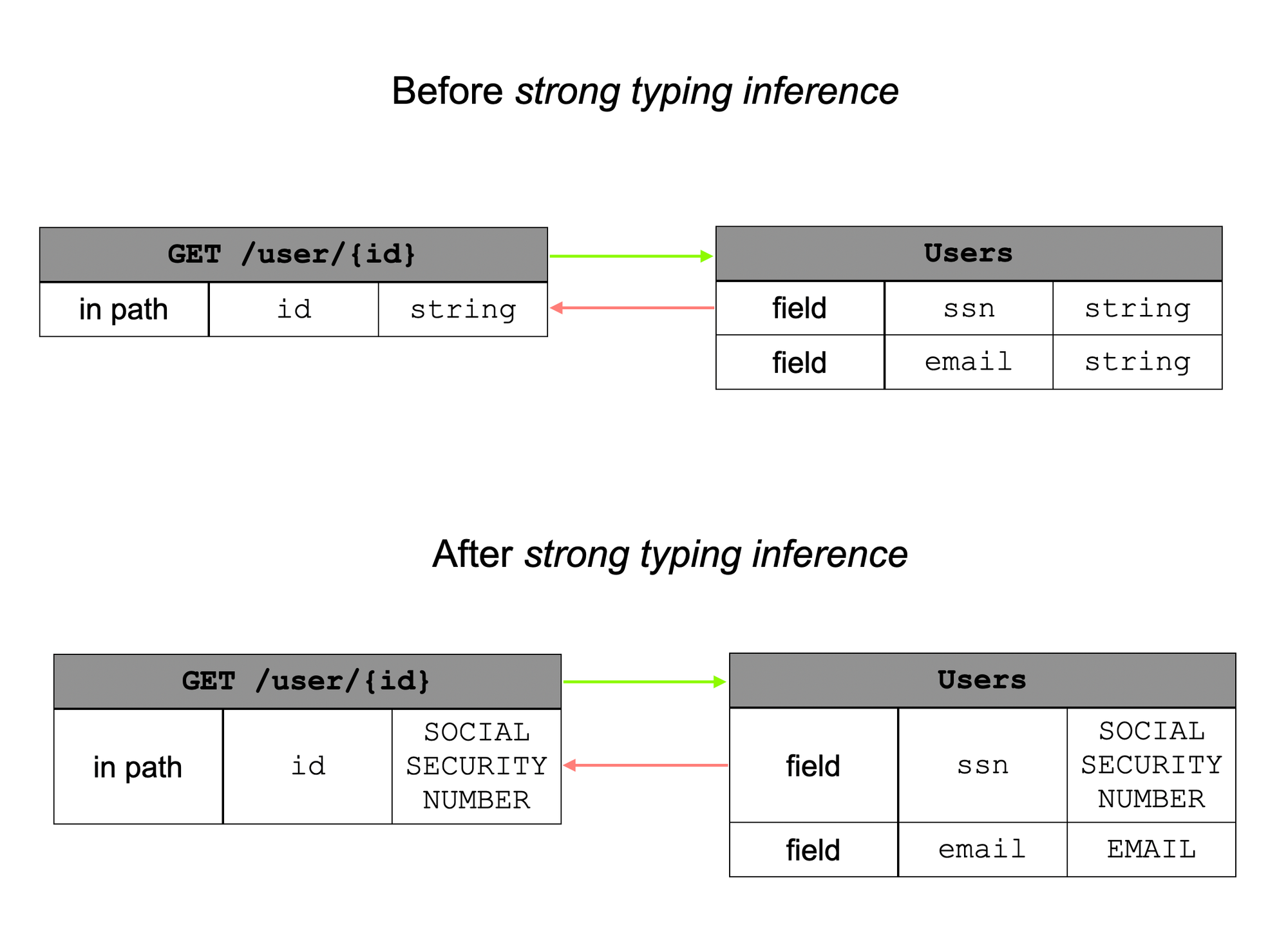
In fact, Strong Typing and Sourcing Inference draw three major conclusions:
- The
ssnfield of theUserresource and theidparameter of theGET /user/{id}resolver are connected. When we retrieve assn, it will be relevant to reinject it as theidparameter of theGET /user/{id}field in a subsequent request. - The
ssnfield of theUserobject is typed as a string but it is aSOCIAL SECURITY NUMBER. Hence, we type thessnfield more precisely as a social security number. - Given that the
idparameter of theGET /userResolver is linked to theidfield of theuserresource, it must also be typed as a social security number.
Naturally, we also know that the email field of the user object should be typed as an EMAIL, and not a simple string.
Metagraph Initialization
To illustrate our point, let's revisit our example:
- The database is empty. To test the business logic of the API, it's necessary to first populate it with some
Users. That's why, during the initiation phase, thePOST /userresolver, which takes 2 parameters (email,age), will have the highest weight in the graph and will therefore be sent first. Sending a working request to this resolver first is essential for the other 2 resolvers to make sense. - The
GET /usersResolver does not take any parameters and returns a list ofUser[], which, according to sourcing inference, is necessary to have aUseridessential for executing a valid request on theGET /user/{id}resolver. It will, therefore, have a higher weight thanGET /users/{id}, which takes anidparameter (which is linked to thessnfield of theUserresource) and returns a singleUser.
Thus, we perfectly understand the dependencies between the types of requests and the different sequences of requests that make sense a priori, even before having sent any request.
The reinforcement iteration
Next, and this is the concept of feedback-driven semantic API exploration, the AI learns iteratively to interact with the API, according to the following reinforcement algorithm:
- Select the path with the best weighting
- Ask the oracle to fuzz it with the most coherent values possible (which respect the inferred types, and the sourcing relations found at initialization)
- Send the request
- Analyze the returned response and store the new information collected, which can be reinjected in the following iterations
- Re-infer the types, dynamically this time to better match the real exchanged types. Without going into details, here we can perform inference on the returned values directly, and not on the documentation context. This notably allows us to detect data leakage.
- Update the weights of our MetaGraph
What about GraphQL and other kinds of APIs?
As mentioned earlier, we managed to build one single abstract model that supports all kinds of APIs at once. If you're interested in how this applies to your APIs, we'd be happy to walk you through a real-world example during an Escape's demo with our product expert. The only pieces of the algorithm that are different are the Schema parsers (in input) and the Client that formats sends requests to the API.
For example, in GraphQL, the Resources are the GraphQL Objects, the Resolvers are all the non-cyclic Paths of the GraphQL API, and the whole algorithm is recursive.

What about Generative AI?
Lately, generative AI has been all over the place in the security world. However, its widespread use in discussions within the security vendor space often lacks clear explanations of its implementation. Generative AI enables Escape to send increasingly relevant requests, especially in 2 cases:
- Just after initialization: at the very beginning of the algorithm, when we have no requests, we use generative AI to send some particularly relevant initial requests. This allows us to hot start our algorithm.
- When receiving Bad Requests (usually
400status code for well-designed REST APIs), feeding the error message (sometimes quite verbose!) to an LLM, along with the original request, is particularly relevant to resending the fixed and valid request. - During security tests; some complex attack scenarios require a deep understanding of the business logic context. In some cases, generative AI can make particularly relevant decisions, enabling us to improve the success rate of specific attack scenarios.
How do we tackle the security?
Security tests
Thanks to the preceding algorithm, in addition to having covered the entirety of the API and generated legitimate traffic, we can replay a particular sequence of requests in order to test a specific resolver within a specific context.
Thus, assessing complex attack scenarios becomes straightforward. Instead of building specific tests for any kind of API, we focus on the abstract flows around the MetaGraph.
Since our entire DAST (Dynamic Application Security Testing) architecture is event-based, security checks are built as middleware over the exploration algorithm described above.
We defined 100+ complex attack scenarios on this abstract flow, and now it's possible to create your own in a few lines of YAML code with Escape Rules as well.
Consider the advantages over static checks like Nuclei or bChecks. As a security professional, you have the capability to create custom security tests for your entire organization with a single click, without requiring ongoing maintenance. It is your additional superpower in identifying business logic flaws. Additionally, there's no need to involve your development teams; you can utilize Escape's community to develop these checks for you.
Sensitive data detection
In addition to the static Strong Typing Inference presented earlier, which is static and only performed at the initialization of the MetaGraph, Escape also performs dynamic inference during the reinforcement iteration loop. Every single response returned by the server is analyzed by a memory-efficient inference algorithm able to detect the precise type of every single data present in the response. This allows Escape to detect more than 800+ data types, including 300+ of critical sensitivity – secrets, tokens, personally identifiable information, etc.
Static and dynamic inference now makes the task and the results extremely reliable.
Benchmark against former technologies
So what about the results? We invite you to take a look at our benchmark on GraphQL and REST applications against OWASP ZAP and StackHawk.
Conclusion
We hope that now we answered your question: how does it work?
Escape's innovative algorithm, rooted in Feedback-Driven Semantic API Exploration (FDSAE) principles, addresses this complexity by autonomously generating legitimate traffic to test API's business logic.
Through techniques like Sourcing Inference and Strong Typing Inference, Escape ensures the accuracy of generated requests, while integration with generative AI enhances adaptability, particularly in complex attack scenarios.
By providing dynamic, event-based security checks aligned with abstract API flows, Escape empowers security professionals to detect and mitigate business logic flaws effectively, while also enabling sensitive data detection.
And even better than that, Escape offers the ability to create your own Custom Security Checks, benefitting from this unique technology, that does not need maintenance over time.
With Escape’s proprietary technology, you don’t just find security flaws—you prevent them before they become breaches. If you're curious to see Escape in action, we'd be happy to walk you through a quick demo session with our product expert—tailored to your applications!
💡Want to learn more? Discover the following articles: