Why security engineers need a new approach to identify business logic flaws


In the last decade, security scanners have evolved to identify common vulnerabilities like SQL injections.
But that’s just not enough anymore.
In 2024, data leaks in applications come from exploiting business logic flaws. In the next few years, applications will grow in size and number too fast, so the true advantage will come from being able to find business logic vulnerabilities at scale.
The growing diversity of security tools changed the way we secured our applications in recent years. The next paragraphs may well change the way we secure our applications in the years to come.
Static analysis and Nuclei templates are not enough
In the security industry, we've witnessed a significant influx of security tools in recent years, offering solutions for various aspects like Cloud security testing, IaC, Container scanning, ASPM, Secret scanning, SAST, DAST.. . You name it.
We’ve heavily shifted towards securing applications before their release in production and helping developers write more secure code. Especially for the latter - tooling to help developers write more secure code has improved. We’re no longer used to long scan times or tools looking like security-oriented linters, turning whole IDE in red for very little value.
SCA tools like Snyk have appeared to ensure the packages we use do not contain any vulnerabilities.
Static analysis tools, which find injections and other bad coding practices, have become more developer-friendly and accessible with solutions like Semgrep.
Simple tools to test known vulnerabilities on web applications also have appeared, with some open-source ones like Nuclei being very good at it.
Yet, it didn’t stop data leaks from happening. Let’s be honest, static tools come with multiple limitations. Simultaneous to those improvements in the industry, from 2015 to 2022, data breaches in the healthcare industry rose more than twofold, from 270 to 707 per year.
How is that possible? How do we get better tooling to write secure code and find software vulnerabilities, and yet our applications are getting more and more hacked?
There are two explanations for this:
- Our apps get more secure, but we expose more and more of them to the internet. Exponentially more, actually.
- Even if we got better at finding technical vulnerabilities, nothing in our current tooling, from Snyk, to Semgrep to Nuclei, can find anything related to business logic flaws and access control vulnerabilities. As applications get more complex, with more features, user roles, and access control rules, those flaws become increasingly common. For instance, Gitlab’s API has access control vulnerabilities uncovered almost every month of the year now.
Why is it hard to test business logic at scale?
Finding business logic flaws at scale is hard from a technical perspective. Let’s say you have an application that allows your users to access their bank accounts.
The application is based on an API with a GET /user/[id]/account route.
One of the most obvious business logic flaws would be to forget to implement proper access control on the route, in a way that allows any authenticated user to access information from other accounts just by replacing the ID in the URL.
GET /user/{victim_account_id}/account => 200 OK
This type of vulnerability is called a BOLA, or Broken Object Level Access Control, and it’s a part of the 10 most common vulnerabilities in API according to OWASP.
Now, suppose that you want to write a test using Nuclei to ensure that user A cannot access user B’s account:
requests:
- method: GET
path:
- "{{BaseURL}}/user/{{victim_account_id_1}}/account"
- "{{BaseURL}}/user/{{victim_account_id_2}}/account"
headers:
Authorization: "Bearer {{token_user_A}}"
matchers-condition: and
matchers:
- type: status
status:
- 200
While this might work, it has several important limitations:
- To write this test, you actually have to describe exactly the vulnerability. In practice, most vulnerabilities appear in cases the developers didn’t think about in the first place.
- This tests only one possible vulnerability on a single route of your application. You will have to think about all possible exploitations in all routes of your application and write a test for each if you want to ensure proper testing.
- This test relies on the variables
victim_account_id_1andvictim_account_id_2existing in the database during your tests. If the database evolves, if any route pattern changes, your test becomes obsolete, and you must update it accordingly. And what’s worse than writing tests? You got it, maintaining tests.
Consequently, writing and maintaining a proper set of business logic security tests for an API and an application is proportional to (number of features) x (number of possible vulnerabilities) x (number of fixture parameters)
Let’s try to evaluate what that means for an average-sized application:
- As for the number of features, it’s proportional to the number of API routes. From our experience at Escape, most applications average 100 routes at least.
- Typically, vulnerabilities from one web application to another are pretty similar. OWASP’s Common Weakness Enumeration (CWE) project enumerates the possible defects that lead to vulnerabilities appearing in software applications. Having tests for their OWASP CWE Top 25 is quite a good starting point for ensuring proper security, so the number of vulnerabilities to test for would be 25.
- Finally, when it comes to fixtures, let’s take the hypothesis that routes have on average 5 parameters and that our fixtures contain 2 different values per parameter. That’s 10 fixtures per route.
So, ensuring proper business logic security testing for our application would require writing and maintaining 25 tests x 100 routes x 10 fixtures = 25,000 tests for an average-sized application. That’s totally impractical.
Introducing Escape rules: Business logic security testing reinvented
What if instead of specifying our tests, we could just write simple rules like “No admin routes should be accessible to unauthenticated users” or “No user should be able to access another account than his own”, and then let a program generate test cases for us according to our API structure and what’s in our database?
This is what we think security engineers deserve. So we decided to create it. There are three things we did to make this possible:
- Generalise tests across API routes. This can be achieved quite easily using templating like selecting “all routes containing /admin” or “All routes that manipulate personal data” instead of writing one test per route. The list of routes and parameters can be fetched from various easily accessible data sources: OpenAPI/Swagger files, Postman collections, or live traffic logs.
- Automatically fill the API route parameters with fixtures that exist in the database. This part is the hardest, technically, and it took us two years of research to create a solution that we called “Feedback Driven API exploration”.
- Invent a simple language or syntax to describe the test with route matchers, custom payloads, and an assertion system. We decided to go for a YAML-like syntax for easy test writing.
This is how Escape rules were born, a simple yet powerful YAML based language to write API business logic tests that are agnostic of the exact API routes and fixture data.
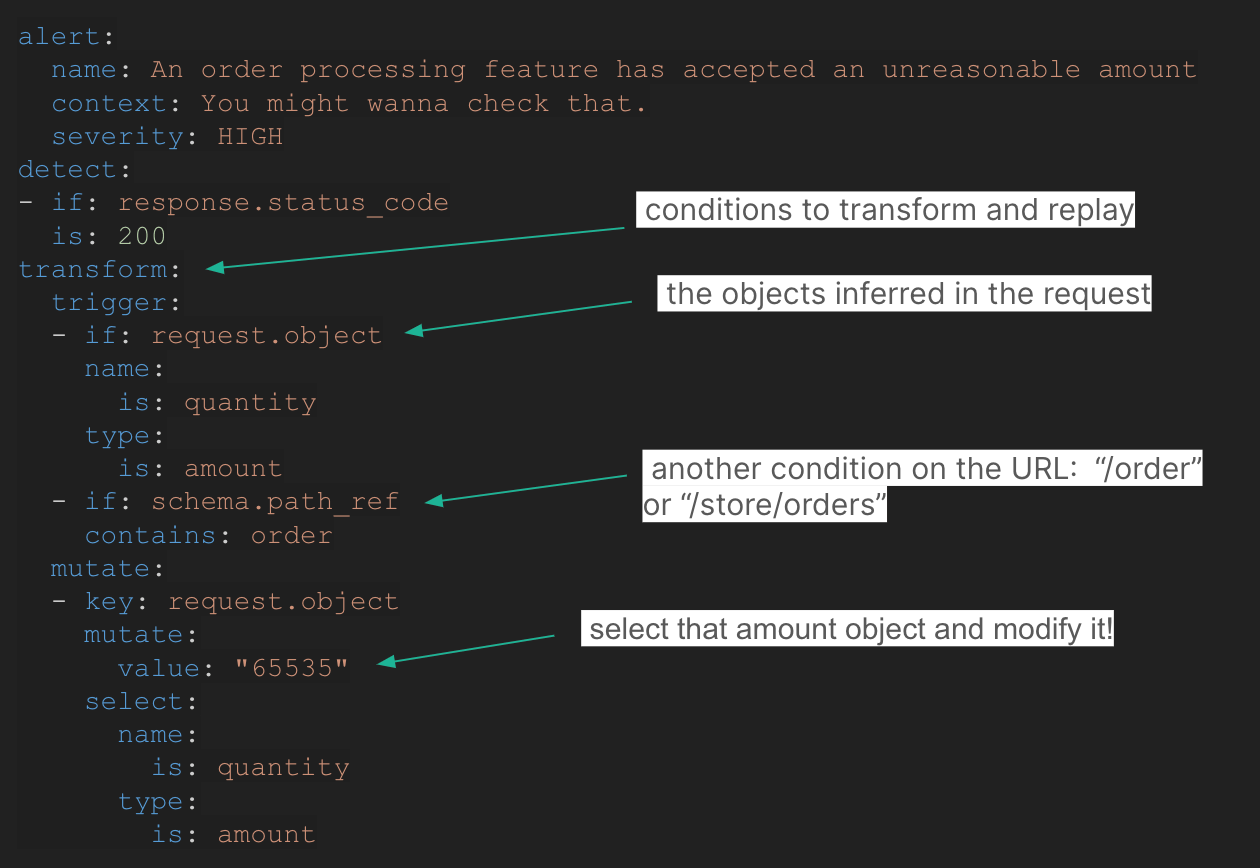
Tailored to your APIs, zero maintenance required
Until now, security engineers had to balance running generic, low-configuration security scans versus tailored tests that required a lot of maintenance over time. This is over thanks to Escape’s contextualized rule engine.
Despite their ability to test the business logic, Escape rules require zero maintenance. They don’t need to be tied to explicit routes or HTTP parameters. They adapt to the evolution of your existing APIs and new APIs without the need to maintain the ruleset. By design, they are resilient to evolving database fixtures in development environments.
With Escape rules, you can code a test once and forget about it, it will run on all your APIs and all your API updates, be it in CI/CD, development, or production environment.
Designed for maximizing the ROI of your Bug Bounty and Pentest programs
While bug bounty programs and pentests are the most in-depth security assessment available today, the final check between an application and the wild internet, they have an inherent limitation: they are slow and point in time.
In most organizations, nothing prevents a junior developer from implementing again the same issue that had been detected by the bug bounty program and fixed years ago.
As powerful as they are, pentests and bug bounties depend on the developers' memory, and any turnover can make the same issues appear repeatedly.
Escape rules are changing this. Escape rules are so powerful that they can describe and detect a wide range of attack scenarios from the basic SQL injections or SSRF too, especially, efficient for complex multi-steps and multi-user access control problems like tenant isolation issues.
Consequently, most of what an API pentest or a bug bounty program can find can be quickly implemented as an Escape rule for fast detection at scale and in the CI/CD.
With Escape rules, you can capitalize on your pentest and bug bounty programs, implementing a new business logic test every time a new issue is manually detected, preventing them from reappearing elsewhere and ultimately creating a resilient organization.
Powered by the community, like the future of cybersecurity
Back in the old days, security engineers were focused on their specific applications. But in this era, sharing knowledge is absolutely mandatory. And was even sought by some of the security engineers we talked with. Imagine you’re running an e-commerce platform, who said that a business logic test for one couldn’t be reused for another?
Rest assured, we were mindful of that fact when launching Escape rules. While many security tools only have in-app functionalities, we created a GitHub repository with all custom security tests developed by the community and accessible to everyone.
Using it, security engineers from the community can collaborate on rules, create new ones, and share their own with their peers to create a network effect of detections.
Whether you need to explore it by vulnerability type or technology, it’s all there.
Welcome to the world where business logic vulnerabilities can no longer escape
In the new internet order, everything is an API and every API is at risk. Business logic flaws in APIs are have become the most common security issues found by bug bounties and are overwhelmingly present in critical data leaks.
Until now, it was very hard for security engineers to find them at scale, because they are tied to the application’s custom logic, unlike vulnerabilities in dependencies and code smells found by SCA and SAST.
Thanks to Escape rules, our new easy-to-use yet powerful YAML-based language, we now live in a world where security engineers can quickly detect business logic level vulnerabilities at scale in all their APIs and applications, in all their environments, at zero maintenance cost.
Even better, they can share their business logic flaw detection rules with the community and collaborate to create more resilient applications and organizations. With Escape rules, security engineers are ready to secure an internet where API sprawl is a reality.
💡 Want to explore more about custom security tests? Check out the following articles and videos:
- Workshop: How to write custom security tests for your APIs: