How we built Escape DAST's proprietary web application crawling algorithm and what makes it innovative
In this article, we'll show how we created our web application crawling algorithm to ensure complete testing coverage for modern applications.




Web security testing in modern complex, highly dispersed and fragmented environments is hard. Actually, this is a mission that old-school DAST solutions like Qualys , Rapid7 or Tenable have difficulties to handle.
Web applications have undergone significant evolution, transitioning from basic Multi-Page Applications (MPAs) to more sophisticated Single-Page Applications (SPAs), and even hybrid models that integrate both. While these advancements have greatly improved user experience, they have also expanded the attack surface and introduced new, more complex security challenges.
This is why it was important (and always fun) for us at Escape to find a way to tackle these challenges from a technical point of view and make sure our algorithms are able to find business logic vulnerabilities in all types of web apps, and especially in SPAs.
In this article, we're proud to explain to the security community how we created the state-of-the-art security testing algorithm that ensures all parts of web apps are sufficiently crawled and tested, and show what makes it truly innovative. You can also find all the references we used for this research at the bottom of this article.
The real challenge: modern web application architectures
In MPAs, each interaction with the application triggers a full page reload from the server. While this architecture remains simple, it comes with performance drawbacks, particularly as the application grows in size.
In contrast, SPAs load a single page and dynamically update content in response to user actions. This approach enhances performance and overall user experience but creates new hurdles, including managing complex client-side routing and maintaining state across diverse user interactions. SPAs are typically built using JavaScript frameworks like React or Angular, adding layers of complexity to both the application itself and the testing processes.
These advances in web application architecture have, unfortunately, broadened the potential attack surface. Vulnerabilities are no longer confined to the server-side, but can also be present in client-side logic or dynamically loaded content. Cross-Site Scripting (XSS), for example, is a prevalent vulnerability in modern applications, particularly those built with JavaScript. XSS allows attackers to inject malicious scripts into web pages, posing serious threats to user security and data integrity. Similarly, vulnerabilities such as Insecure Direct Object References (IDOR) and Open Redirects can enable attackers to exploit weaknesses and gain unauthorized access to data or redirect users to malicious sites.
The widespread use of third-party libraries and external resources in modern web applications also brings new risks. Dependency and supply chain risks are becoming increasingly critical, as attackers may target commonly used packages, affecting a wide range of applications. These risks underscore the importance of thorough security testing, which must account not only for the core application code but also for the libraries and dependencies it incorporates.
How we came up with the idea of the first state-aware web application crawler
Escape DAST is the first DAST to introduce a state-aware web application crawler, designed to navigate complex and dynamic web applications. Unlike traditional crawlers, which are limited to static URL navigation, it uses a finite-state machine (FSM) model to represent web applications, allowing it to map all functional states of the application. We'll provide an in-depth overview of the FSM and state representation in the section below.
By exploring potential user interactions and using content fingerprinting with intelligent deduplication, our algorithm can avoid redundant exploration. The Transition Actions, which link states, are identified with unique identifiers. These identifiers are used to compare actions and ensure that the scanner does not revisit the same actions multiple times unnecessarily.
This FSM-based crawling enables Escape DAST to perform a more intelligent exploration. It can recognize when the application is in the same or a functionally similar state, thereby reducing unnecessary processing. Moreover, by identifying and prioritizing high-risk actions for user interactions, it ensures better scan efficiency and relevance.
FSM-based crawling also allows Escape DAST to emulate realistic user behavior. This feature not only improves scan efficiency but also generates more accurate and easy-to-reproduce reports by tracking the exact navigation path to vulnerable states. Additionally, the scan coverage can be easily represented in a graph-based format.
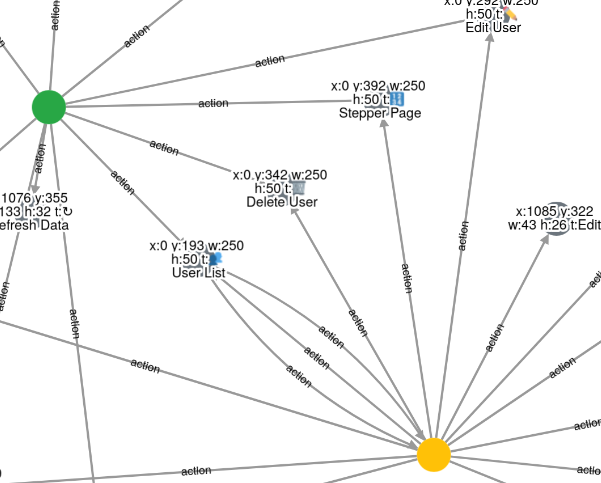
In Figure 1, we see two states: one fully tested (shown in green) and one not yet tested (shown in yellow). The gray circles represent the actions identified. An arrow pointing from a state to an action indicates that the action exists in the state and can be shared across other states, such as Stepper Page or Delete User. The opposite direction indicates navigation by interacting with an action to transition to a new state.
The web application crawling algorithm
So, as mentioned previously, building on this FSM-based crawling technique, the important step in our development process was to define a robust algorithm capable of representing and implementing the web application's coverage in a security scan. The primary objective of our research was to develop an abstract representation of a web application that could be implemented in our security scanner. We wanted to create an abstraction that would allow us to map the coverage of our scans in a way that doesn't depend on URL routing, while still being simple and clear for our end users.
Finite State Machines (FSM)
A Finite State Machine (FSM) is a computational model consisting of a finite set of states, input events, transitions between those states, and a starting state. In an FSM, a state describes the condition of a system, and transitions between states are triggered by specific events.
In the context of a web application, each unique User Interface (UI) would be represented as a state, and user interactions—such as clicking, typing, or hovering—would trigger transitions between these states.
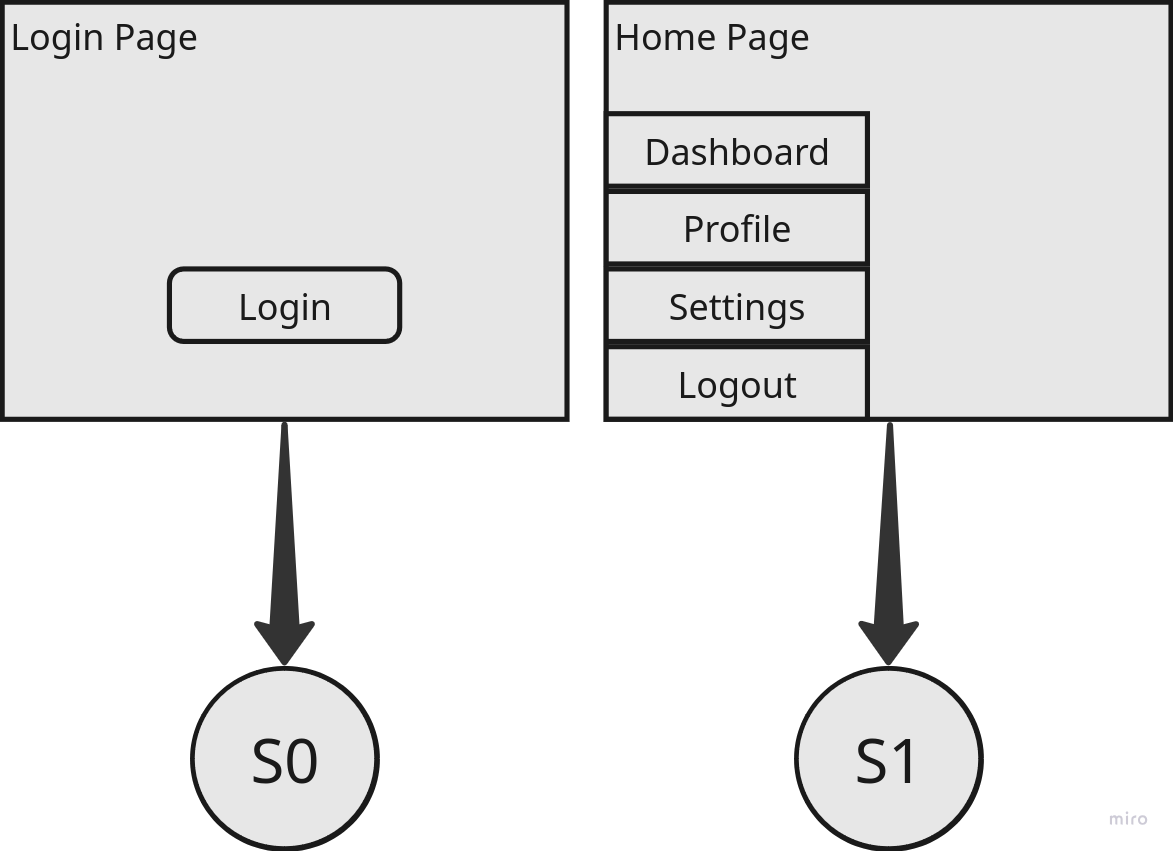
As seen in Figure 2, we can represent two pages, a login page and a home page, as two distinct states, S0 and S1. Each action, like clicking a button or filling in a form, could transition the application into a new state. These user interactions, which result in state transitions, are called transition actions.
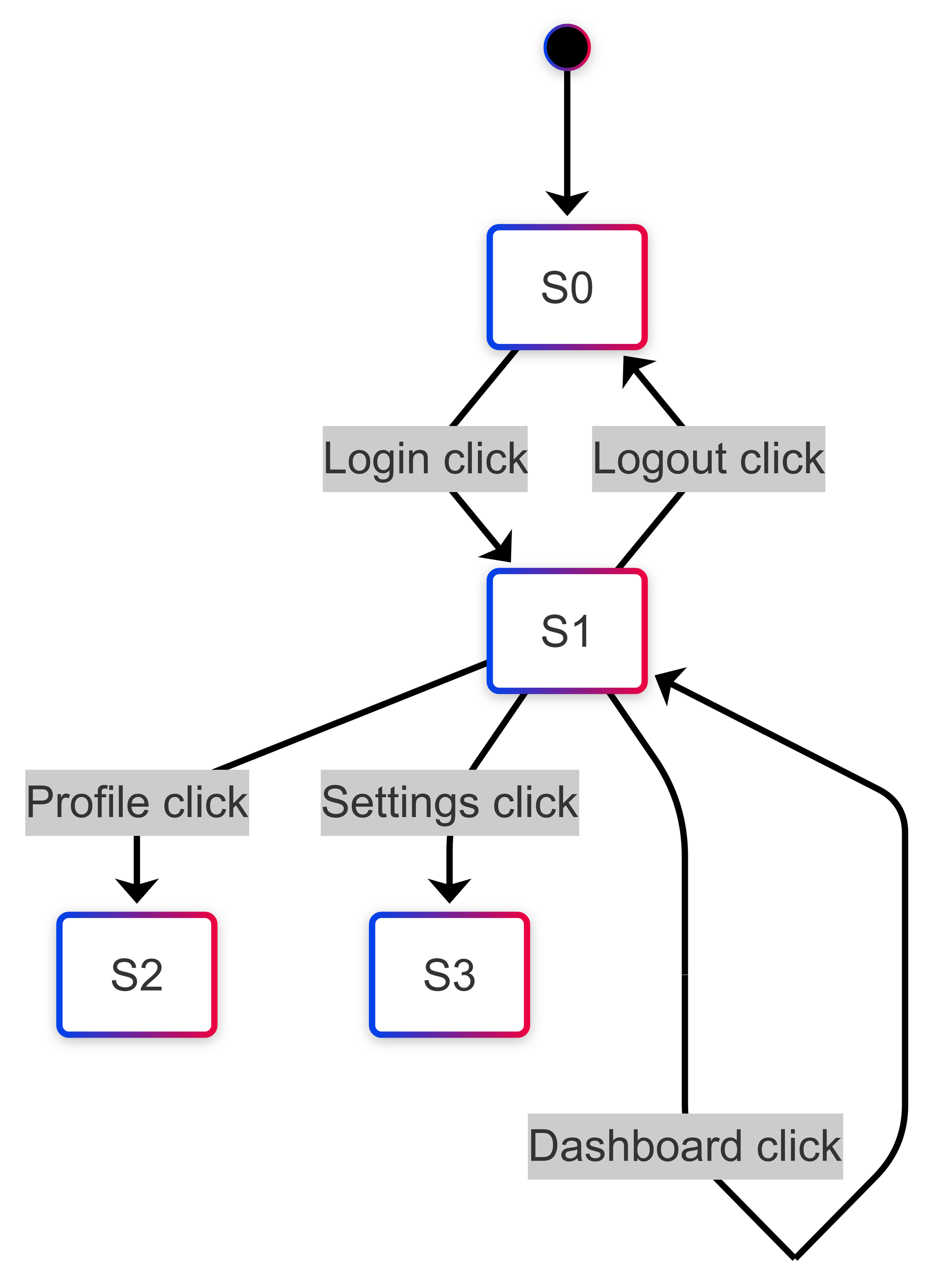
In Figure 3, we expand the FSM representation to show the progression of states in the application after interacting with all navigation buttons. Here, S0 represents the Login Page, S1 is the Home Page, S2 is the Profile Page, and S3 is the Settings Page. By using this FSM abstraction, the scanner can intelligently explore the application, focusing on meaningful user paths instead of blindly requesting URLs. This method helps map the attack surface more accurately and speeds up the scan by optimizing navigation paths.
State Representation
To create an FSM, the scanner must determine if the application has entered a new state after an action. This raises two important questions: What is a state? and How do we identify duplicate or similar states?
A state can be defined using various methods, such as the DOM structure, visual representation (e.g., screenshots), visible text, interactive elements, or even API calls made. These features allow the scanner to determine whether a new state has been reached or if the system is revisiting a previous state.
We identified two types of states:
- External State: This state can be accessed directly via a URL.
- Deep State: This state can only be reached by performing specific transitions, often without changing the URL.
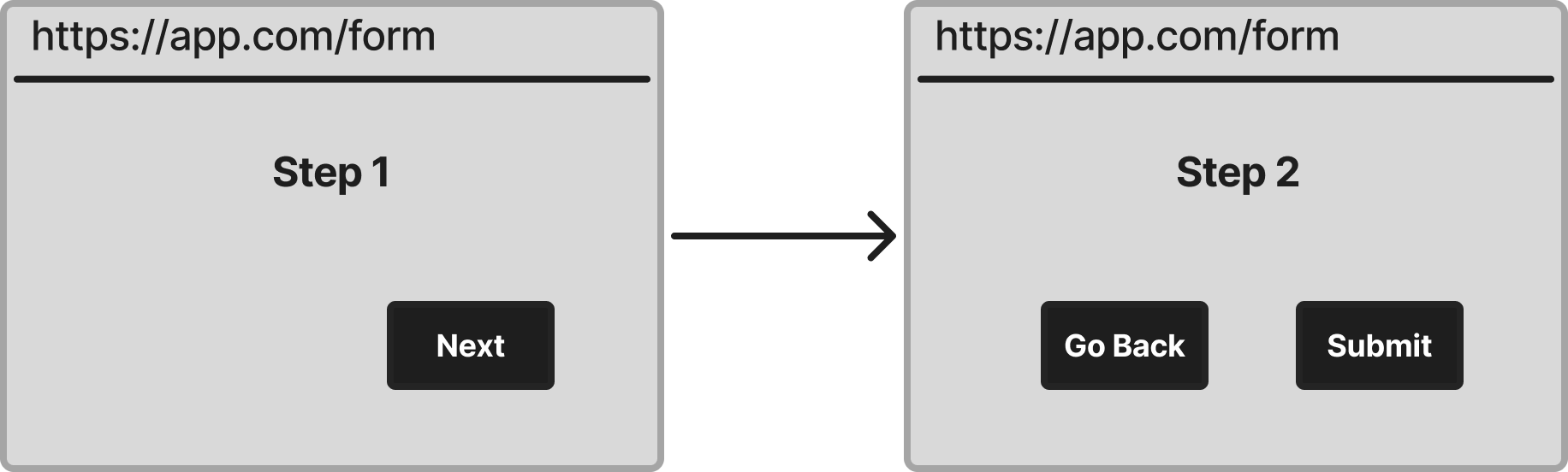
In Figure 4, we can see a multi-step form where step 2 cannot be reached directly by URL; it can only be accessed after completing step 1. This represents a Deep State, while step 1 is an External State since it can be directly accessed via a URL.
As a security scanner, our primary concern is how to represent and identify states accurately, especially when it comes to avoiding the state explosion problem—the issue of excessive state duplication. To address this, we tested several methods and techniques to identify meaningful states while minimizing unnecessary redundancy.
Methods for Identifying States
DOM Tree
In dynamic web applications, elements can change frequently due to JavaScript manipulation. Using literal DOM content could lead to a state explosion, as slight variations in dynamic properties might be considered a new state. Instead, we explored the use of the DOM hierarchy structure, which strips dynamic attributes and focuses on the logical structure. However, this approach has limitations when dealing with pages that display lists of dynamic content, such as a list of active users.
To address this, we experimented with locality-sensitive hashing (LSH), a technique that generates the same hash for data with similar structure. While LSH performed better in identifying similar structures, it was memory-intensive and required more samples before yielding accurate results.
Visible Text
Visible text can also help identify states. However, text that changes frequently, like timestamps or real-time data, can be unreliable. Larger text elements, such as headings or titles, provide more stable indicators, but they cannot always guarantee accurate state identification.
URL
URLs are useful for identifying unique states, especially for applications that rely on traditional URL routing. However, this is not always effective, particularly in Single-Page Applications (SPAs), where transitions may not update the URL. This limitation becomes evident in Deep States that are only accessible via transitions and do not change the URL.
Interactive Elements
We also considered identifying states based on visible interactive elements on the page, such as forms, buttons, and input fields. This approach helps define states by the functionality they provide. However, pages without interactive elements might be incorrectly detected as a single state, leading to a lack of granularity in the scan.
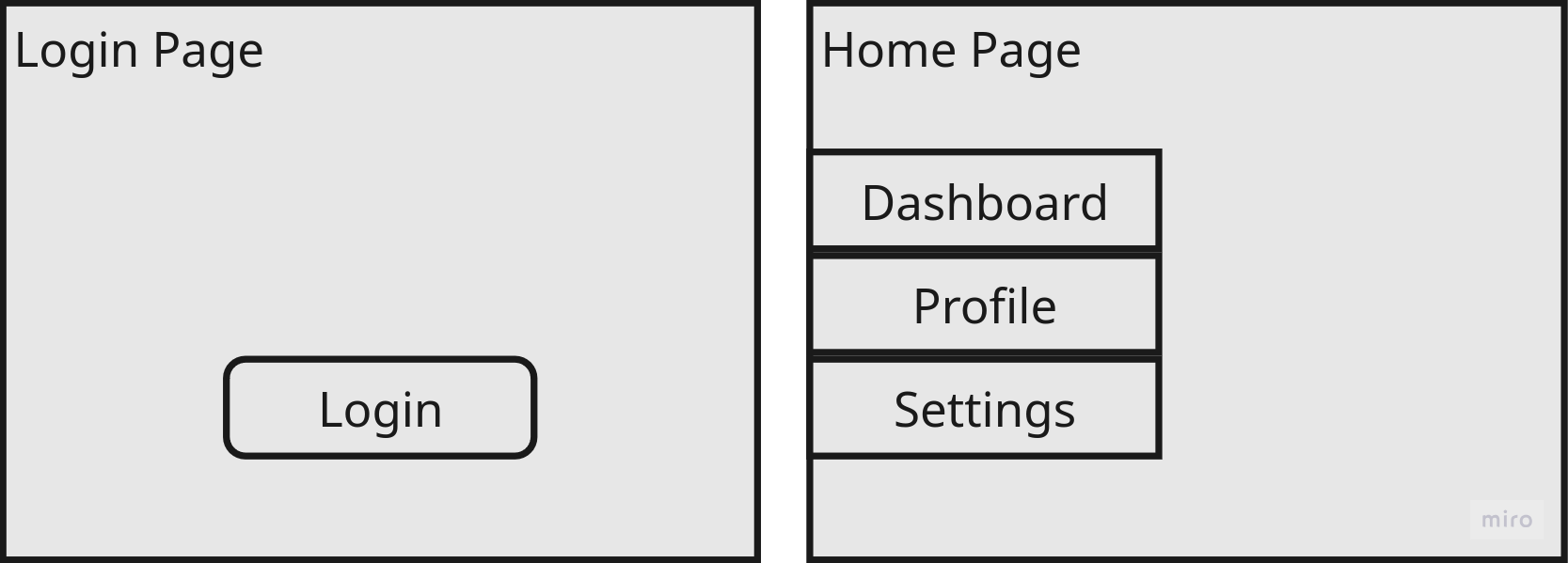
In Figure 5, we see two pages with different interactive elements: the Login Page with one button and the Home Page with four navigation buttons. These are correctly identified as two separate states.

In Figure 6, however, two pages that contain no interactive elements would be identified as a single state, despite being visually and functionally distinct.
Screenshots
Another method we explored was using screenshots to compare the visual representation of the page. While intuitive, this approach only works well for static pages. Dynamic content, such as rotating banners or user-specific information, causes even slight differences in the screenshots, making this approach less reliable for modern, dynamic applications.
We experimented with perceptual hashing and other image similarity techniques to compare screenshots more efficiently, but these methods struggled with high-frequency noise, such as animations or user-generated content. Additionally, screenshot-based comparison introduces performance overhead, especially when images must be processed and compared repeatedly.
AI Agent
We also considered using an AI agent, such as Large Language Models (LLMs) like Gemini or OpenAI's o4-mini, to identify unique states. While this approach produced precise results, it was resource-intensive due to the large execution context that needed to be maintained during the scan. This resulted in higher operational costs and would not be feasible for large-scale scans. That being said, we're still exploring how we can enhance scanning results with the help of different algorithms and advancements in LLM-assisted crawling. Stay tuned for more news here!
Classification Model
Finally, we treated state identification as a classification problem, using features like the URL, screenshot, DOM structure, interactive elements, and visible text to train a model. This model could be continuously improved using reinforced learning during the scan's discovery phase, allowing it to adapt over time. The model would eventually assign scores to features based on their relevance for state changes, improving accuracy in future scans.
Going beyond just scanning
Adaptive Learning Scanner
Using the FSM abstraction, we made sure that Escape DAST not only performs the scanning but also optimizes the scanning process by intelligently prioritizing paths based on the score assigned to them. This adaptive scanning method ensures that higher-risk paths are tested first, maximizing coverage while minimizing time spent on low-value areas.
The FSM model generated during the scan can be persisted and reused for future scans, making the scanning process much faster and more efficient. With each new scan, Escape DAST optimizes the scanning process, adapting to any changes made since the last scan. This adaptive approach allows Escape DAST to detect changes across different versions of the application with minimal overhead.
The system also allows experimentation with various state identification techniques, such as using interactive elements, visual similarity, and AI classification models, ensuring that Escape DAST remains flexible, accurate, and adaptable to different scanning needs. The ability to create a specific model for each target, which can be saved and reused in subsequent scans, increases the precision of vulnerability detection.
Integration with API Scanner
Another key challenge we faced was ensuring that Escape DAST integrates seamlessly with the existing API security testing tools at Escape. By reusing existing inference and security checks, it now allows for a unified process that tests both the front-end and back-end surfaces of the application.
As with a web application algorithm, we built out our proprietary Business Logic Security Testing algorithm for APIs in-house. You can find more information about how we built it and what makes it innovative in this article.
This integration enables synchronized discovery and testing of the entire application, covering both visual workflows and hidden endpoints. The API scanner also benefits from receiving more realistic and valid data flows, which improves the chances of successful exploitation and enhances the accuracy of the findings.
Automatic OpenAPI Spec Generation
As part of the crawling and scanning process, Escape DAST now also automatically generates OpenAPI (Swagger) documentation by analyzing API interactions and JavaScript code used within the web application. The initial research on this topic, on how we came up with the idea of building a tool to generate the most relevant parts of the specification for our API exploration technology from API codebases, was mentioned here. Now, this automatic process helps provide better visibility into undocumented systems and gives developers accurate and up-to-date API specifications without the need for manual input or the interception of production traffic.
With the integration of multi-user scanning, Escape DAST can map different API actions to specific user roles. This allows the API scanner to more precisely test for role-based access control (RBAC) issues, generating richer and more detailed specifications that aid in identifying potential vulnerabilities related to unauthorized access.
Authenticated Scanning
To ensure comprehensive coverage, we also made sure Escape DAST supports authenticated scanning across both single and multi-user contexts. This capability enables the detection of access control flaws by correlating findings across different user roles, making it particularly effective for identifying multi-tenant data leaks.
Traditional scanners, which often operate under a single authentication context or rely on hardcoded credentials, lack this flexibility and capability.
Modern scanners might support complex authentication flows with multiple users through various methods but often have no ability to debug and see where the authentication went wrong during scanning. See this quick overview of top 5 modern DAST tools table for more precise information related to authetication.
Escape DAST supports multiple authentication methods, such as OAuth, header, token, cookie, and local/session storage injections. It can maintain an active session throughout the scan, detecting any disconnections or session changes.
Before every scan, Escape DAST automatically validates the provided scan configuration and after every update. Additionally, the user can visually track the authentication flow through screenshots and event logs, which show the steps taken, tokens identified, and more.
Comparison with other existing solutions
Several DAST tools are available in the market, both open-source and commercial, designed to identify vulnerabilities in web applications, like OWASP ZAP, Burp Suite DAST, or Invicti.
Although OWASP ZAP is a powerful tool, it requires manual configuration for authentication and has difficulties dealing with dynamic content, especially in SPAs. Burp Suite, another widely used tool, is feature-rich but also encounters challenges in handling SPAs, especially those involving client-side routing and conditional rendering. Commercial solutions like Acunetix and Invicti provide better handling of dynamic content but still face issues with complex authentication flows and multi-step interactions that are common in modern applications. We've already published a benchmark on the API side and are planning to release a benchmark on the web app side in the upcoming weeks.
The main limitation of many existing tools is their inability to fully support the complexities inherent in modern web applications. They often fail to accurately map the application states or detect deeply nested routes, which are critical for achieving comprehensive security testing. Moreover, these tools often revisit the same application states repeatedly, leading to inefficiencies and an increase in false positives.
Conclusion
To wrap up, we've engaged in the technical aspects, from FSM-based crawling to state identification techniques. This path has led us to a practical solution that tackles the challenge of scanning and testing modern Single-Page Applications.
As we mentioned, our algorithm introduces a fundamentally different approach to dynamic application security testing by modeling the application as a state machine. Instead of blindly interacting with the app, it focuses on identifying interactive elements and simulating realistic user actions. This state-based approach not only enhances coverage reports with detailed states, screenshots, and interactions but also optimizes scan durations and boosts scan accuracy through AI-assisted crawling, state detection, and security testing.
And of course, we made sure Escape DAST’s state-aware crawling engine integrates deeply with API scanners, automatically generates OpenAPI (Swagger) specifications, and supports authenticated scans with an easy-to-set-up, debug-friendly configuration, ensuring both accuracy and maintainability.
Research references
If you're curious what resources we used for our research, check them out below:
- Dependency-Aware Web Test Generation
- Crawling AJAX-based Web Applications through Dynamic Analysis of User Interface State Changes
- Jäk: Using Dynamic Analysis to Crawl and Test Modern Web Applications-
- Locality-Sensitive Hashing for Efficient Web Application Security Testing
- Representing Web Applications As Knowledge Graphs
- Detection of Changes in Web Applications to Enhance Security Testing
- Using Semantic Similarity in Crawling-based Web Application Testing
- Perceptual Hasning - Looks Like It
- A Deep Dive into Hierarchical Density-Based Clustering
- An MLLM-Assisted Web Crawler Approach for Web Application Fuzzing
- Leveraging LLMs for Task-driven Web App Scanning
- Neural Embeddings for Web Testing
💡 Want to learn more? Discover the following articles:
- Escape Research: Escape's proprietary Business Logic Security Testing algorithm
- Escape Research: How to automate API Specifications for Continuous Security Testing (CT)
- Escape Research: How we discovered over 18,000 API secret tokens
- DAST is dead, why Business Logic Security Testing takes center stage
- 2025 Best DAST tools