Methodology: How we discovered over 18,000 API secret tokens



Hey there!
It's just the beginning of the year, but our security research team has been working hard to identify current API security challenges.
So for the Escape team, January went under the tagline "API secret sprawl" (we thought it was more fun than"Dry January", and we hope you agree with us 😉).
If you're in the security field, you might mention that the beginning of the year usually marks the release of all "State of.. " reports, taking a look at the past year's trends. Instead of collecting opinions or our tool data, we decided to look at the real world. That's how the whole project started, and we were shocked at what it led to.
Our security research team scanned 189.5M URLs and found more than 18,000 exposed API secrets. 41% of exposed secrets were highly critical, i.e. could lead to significant financial risks for the organizations, as exposed financial tokens and API keys included $20 million in vulnerable Stripe tokens.
Unlike other reports, Escape’s web crawler analyzed applications in their actual usage scenarios, examining everything from APIs to frontends, including elements that run in the background, like JavaScript. This approach shows how and where API secret keys and tokens are exposed in real-world settings, not only in code repositories.
You can review the complete results in our comprehensive report. Meanwhile, in this article, we'll show you the methodology that guided us to these impressive findings.
Methodology
Development of the web spider
To tackle the complex task of scanning 1 million domains, we developed a specialized web spider. This tool was built using Golang, chosen for its excellent input/output (I/O) throughput, good productivity, and strong support for concurrency. These features of Golang were crucial for efficiently processing large volumes of web data.
For networking, we relied on a library named fasthttp (fasthttp GitHub), known for its high performance. fasthttp was instrumental in enabling our spider to handle numerous network requests swiftly and effectively.
To interpret and analyze JavaScript found on web pages, we used tree-sitter (Tree-sitter), a parser generator tool and an incremental parsing library.
It helped us build a robust mechanism to understand and process JavaScript code, which is a critical component in modern web applications.
The Golang-based spider was containerized and designed to listen on a Kafka (Redpanda) stream. This setup allowed for scalable and efficient handling of data streams.
In terms of secret analysis, we incorporated an existing Python-based service that we regularly use at Escape. This tool, which employs natural language processing, was accessed via gRPC.
The whole solution was deployed on a Kubernetes cluster, leveraging the orchestration.
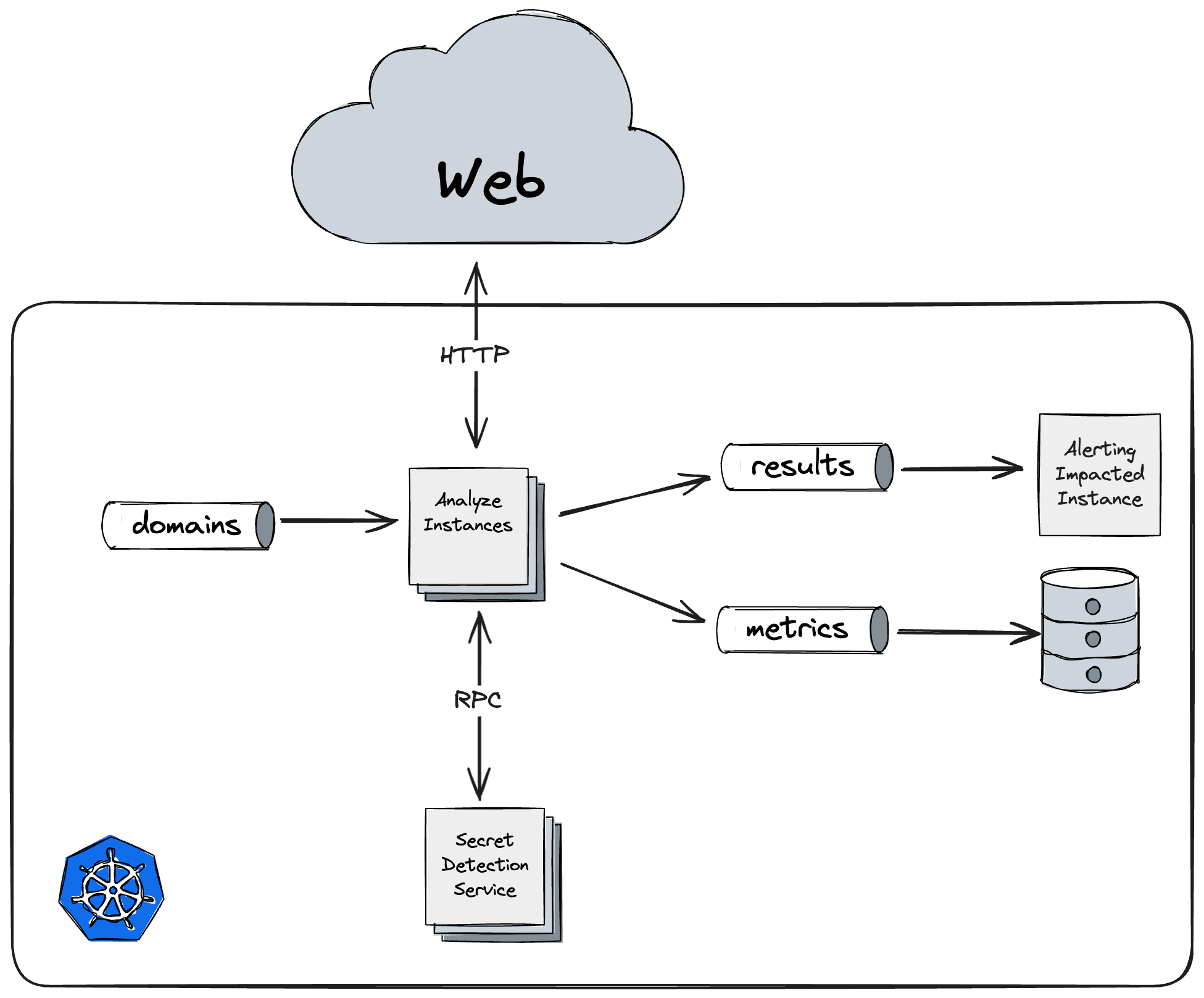
Data gathering strategy
For our comprehensive analysis, we chose to examine the 1 million most popular domains.
The list of these domains was sourced from the Majestic Million dataset, which ranks websites based on the number of referring subnets. This ranking offered us a diverse set of domains to study, spanning various sectors and sizes.
We acknowledge a potential bias in our approach. Typically, larger domains with more resources might have better security measures, possibly leading to fewer instances of secret sprawl. In contrast, smaller websites or those without dedicated security teams might be more prone to such issues. However, our study focused on the most popular domains without specifically addressing this bias.
Alternatively, with over 365 million domain names reported across the internet, our sample size becomes relatively small, potentially leading to greater volatility in the number of findings.
The data collection was a one-time process, based on the latest available list from the Majestic dataset. During the collection, we encountered several limitations. To respect legal and ethical boundaries, we deliberately excluded certain types of domains. This included governmental, educational, and health-related domains, as regular users are not typically authorized to explore these. This decision ensured that our study adhered to the ethical norms of web crawling and data collection.
By focusing on domains that are accessible to the general public, our study provides insights into the state of secret sprawl in the broader, more publicly engaged segments of the internet. This focus enables a comprehensive evaluation of security practices and the challenges encountered in a diverse array of online platforms and environments. Through this lens, we gain a deeper understanding of how secret sprawl impacts various sectors and what this means for the broader digital security posture.
Data collection process
Our data collection process was a significant undertaking, both in terms of scale and technical complexity. To manage this, we deployed our containerized web spider on a Kubernetes cluster. The cluster was capable of scaling up to 150 concurrent worker instances. This level of scalability was crucial for effectively managing the immense task of scanning 1 million domains, allowing us to distribute the workload efficiently and process a vast amount of data.
The collection spanned over 69 hours, with our system analyzing an average of 4 domains per second. This pace resulted in a total sum duration of approximately 30,686,535 seconds for the entire operation. On average, each domain, including its subdomains, was analyzed in about 32 seconds. This comprehensive approach ensured that we not only looked at the primary domain but also dived into the numerous subdomains associated with each, providing a more complete picture of the web landscape.

In total, our process led us to visit 189,466,870 URLs. This extensive coverage was key to ensuring that our analysis was as thorough and inclusive as possible. By examining such a large number of URLs, we were able to gain deep insights into the current state of secret sprawl across a wide spectrum of the internet.
Also, we started this project by making a new tool as a test. It was impressive how quickly this tool was made – just three days by one engineer. Combining this quick tool development with the project's computing cost of only about $100 shows how, in today's world, we can get big results, build solutions without spending a lot of money or time.
Data cleanup and verification
One of the most challenging aspects of our study was, for sure, the data cleanup and verification process. While we could not verify the tokens ourselves, we made sure each one was classified accurately. A common pattern we noticed is that many tokens have specific prefixes. For instance, Stripe tokens have various prefixes, but we focused particularly on live secret keys, identified by the prefix 'sk_live_'.
To improve the accuracy of our findings, we refined our heuristics to filter out only classified information. This meant paying special attention to high-entropy keys, which often represent proprietary, undocumented tokens or false positives, and filtering them even more from our primary dataset. This approach helped us focus on the most relevant and potentially impactful tokens.
Verification of the tokens was a crucial step, and it was carried out by the token owners themselves. We alerted the owners only when our system was highly confident about the findings. This was a delicate balance to maintain – ensuring the accuracy of our alerts without the ability to test the keys ourselves. We had to be very sure before alerting affected parties to avoid any false alarms.
This cleanup and verification process was an intricate part of our study, requiring a nuanced understanding of token patterns and careful judgment to minimize false positives. Our method aimed to provide reliable and actionable insights to those whose security might have been compromised.
Conclusion
Securing all your APIs is hard. It’s even harder when your keys and tokens get exposed involuntarily in real-world settings - from APIs to frontends. Your organization is now not only prone to data breach risks but also to severe financial implications.
Our study reveals that API secret sprawl extends across a diverse array of websites, industries, and domain types. Even modern tech industries are not exempt. Organizations must respond fast, adopting best practices to secure themselves against potential threats.
Not sure where to start? Centralizing token management, enforcing rotation policies, segmenting access, intensifying security training, and leveraging automated testing tools are essential steps to mitigate these risks. We've compiled the comprehensive list in our report.
Need guidance tailored to your specific needs? Feel free to reach out!