How to automate API Specifications for Continuous Security Testing (CT)


While GraphQL APIs are growing in popularity due to their flexible query capabilities, REST currently remains the dominant architectural style for building web APIs. Unlike GraphQL, traditional REST technologies do not inherently provide an interactive schema that clients can use to explore the API. At Escape, we decided to use OpenAPI specifications or Postman Collections as input to a REST scanner instead of GraphQL schema.
However, the following issue arises in this context: not all APIs have an OpenAPI specification available. Even if such a specification exists, it needs to be valid. We completely understand that authoring a specification manually is not a joyful task. This is why we came up with the idea of building a tool to generate the most relevant parts of the specification for our API exploration technology from API codebases.
API specification generator
Our approach involved generating the "path" field within an OpenAPI specification. This field can be broken down into three distinct components:
- The HTTP routes - the endpoints used as input in the Scanner
- The route parameters - a set of parameters are tested during the scan, so it's better to know their names, types, and locations (URL, body, headers...).
- The corresponding route responses - used in the scanner to define the expected response of the HTTP request. Then, we can compare it with the tests carried out in the scanner and discover a possible breach in the API according to a particular payload.

Initially, we focused solely on Spring, Express, and Django repositories. The specification generator comprises two main components: the code parser and the parameter type inference model. The code parser extracts and structures the necessary data from the source code. Then, the parameter type inference model deduces parameter types for non-typed programming languages such as JavaScript or Python.
Code parsing strategy
The parsing strategy is built upon abstract syntax trees (AST). This data structure enables parsing while extracting context relevant to the parsed elements.
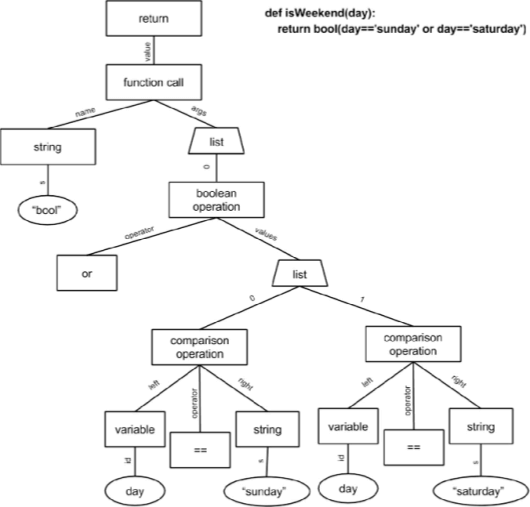
When we look past the nitty-gritty details of specific frameworks, the algorithm we’re working on can be broken down into three steps:
- We use Semgrep to filter files containing fragments of routes.
- Routes are reconstructed from these fragments, and HTTP methods are then extracted. These methods can be defined alongside the routes, in controllers, or within decorators.
- Within controllers, we extract, among other things, parameters that are present in the controller's constructor, as well as the returned element, which is the response. When the returned element is an object, not a primitive, we dive into the models to retrieve the data schema.
Implicitly, you'll grasp that different files are parsed here.
To make the transition from one file to another, we use import statements that link a variable to the file path in which it's defined.
You might notice that each repository is distinct, and such a heuristic approach, as described above, might not be easily generalizable. This indeed posed a significant challenge. However, frameworks do have certain rules we can rely upon, and ASTs provide great flexibility in parsing, then, a generous sprinkle of recursion has made the algorithm reasonably generalizable.
It's important to note that this applies to barebone frameworks: introducing overlays, such as Django's signals library, may yield unpredictable results.
Challenges in the parameter types
Determining the parameter types was another challenge. Let's be clear: guaranteeing the type of a parameter in untyped languages is impossible. To address this, we decided to infer these types based on the following features: parameter name, HTTP method, and parameter localization. The dataset collected from OpenAPI specs consists of about 600,000 points. Our strategy unfolded as follows:
- Remove rows with missing values.
- Vectorize the triplet name_localization_method using the CodeBERT transformer to generate embeddings.
- Reduce the dimensionality of embeddings.
- Use embeddings to train an LGBM classifier model.
- Fine-tune the classifier.
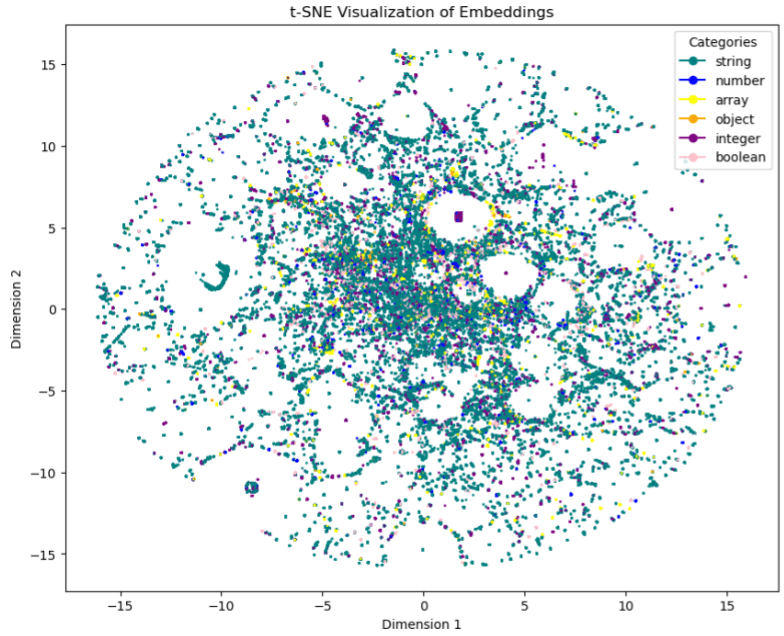
We notice that there are clusters in the form of a beehive - the clusters are small but very dense. Note also that in the middle of the figure, we notice a lot of noise coming from the string class, in addition to the fact that it is in excess in the data set. Conclusion: Penalizing this class in the model training will be necessary.
Training and vectorization were conducted on an NVIDIA GPU to leverage CUDA cores and expedite execution time; otherwise, it would have taken days.
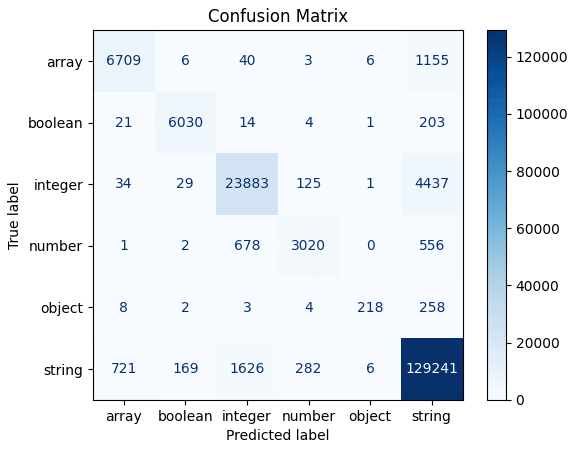
As for the results, we achieved an accuracy score of 0.96, exceeding our expectations. The confusion matrix above suggests that the model faces difficulties when classifying instances belonging to the object and number classes.
We intend to generate specifications incorporating probability values across various types to improve this situation and enhance the Scanner's adaptability. This means that if the highest probability values are relatively similar, we can explore multiple types for testing the parameters.
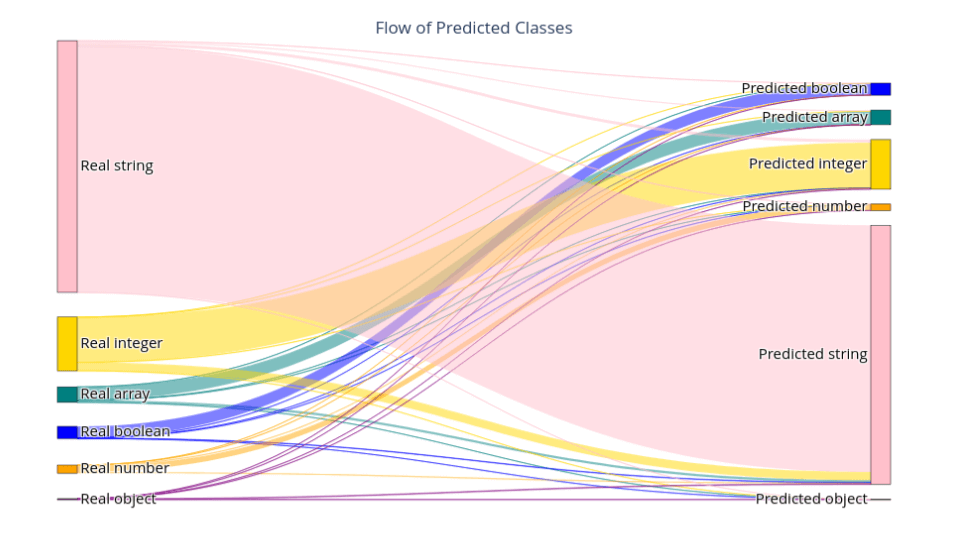
Lastly, the Sankey diagram below offers a visual snapshot of prediction distribution:
Conclusion: Simplifying API specification generation with Escape
To wrap up, we've engaged in the technical aspects, from parsing code structures to identifying parameter types. This path has led us to a practical solution that tackles the challenge of generating API specifications.
Shifting our focus to real-world application, we arrive at the intersection of innovation and practicality. Our solution simplifies the process of creating API specs directly and statically with an understated approach that prioritizes functionality.
In a landscape where REST APIs are prevalent, our tool empowers you to effectively leverage your APIs, whether or not you have an OpenAPI specification. Escape's approach relies on a static methodology, avoiding unnecessary complexity. This emphasis on straightforward analysis streamlines automated API specification generation. Committing to simplicity, we provide a practical avenue for understanding and optimizing API usage.
Need a solution to test your REST APIs?
Escape DAST got your back
Test for complex business logic vulnerabilities without uploading API specifications directly within your modern tech stack
Get a demo with our product expert🧑🎓 Want to learn more about APIs? Check out the following articles: