Guide to handling relational databases with Prisma, NestJS and GraphQL
This articles presents a basic GraphQL application illustrating our methods and guidelines for producing backend code.


This article presents how we implemented our GraphQL API in use at Escape to interact with a relational database. It includes, among other things:
- A quick overview of the different tools provided by NestJS to do GraphQL APIs
- Some guidelines and code examples to serve entities from the database, and especially to handle fields pointing to related entities.
- Our take on solving Prisma N+1 queries in this context.
Like performance and reliability, security is required to ship production-ready applications. But GraphQL lacked the proper tooling, so many teams skipped security...
That's one of the initial reasons why we built the Escape API Security Platform.
Stack and context overview
At Escape, our SaaS solution is powered by a GraphQL backend. This backend is a monolith application built on NestJS, with its Apollo GraphQL server, interacting with a SQL database using the Prisma ORM (Object-relational-mapper).
After such a name-dropping, and if you do not share our stack, you can discover some of these tools if you would like to:
- GraphQL is a query language. It defines a set of rules when designing an API and a query format used to interact with it. GraphQL is not a standalone framework or tool; it is a specification used by other providers to develop their framework for making GraphQL applications, like Apollo.
- NestJS is a JavaScript framework used for building web applications.
- Apollo is a TypeScript implementation of the GraphQL specification, allowing for building graph APIs in JavaScript. It is bundled within NestJS by the @nestjs/graphql package, providing useful decorators for nest-like queries and object declaration.
- Prisma is a TypeScript ORM used for database-related interactions. Using it with NestJS is well documented here.
Coding a basic resolver
Data models overview
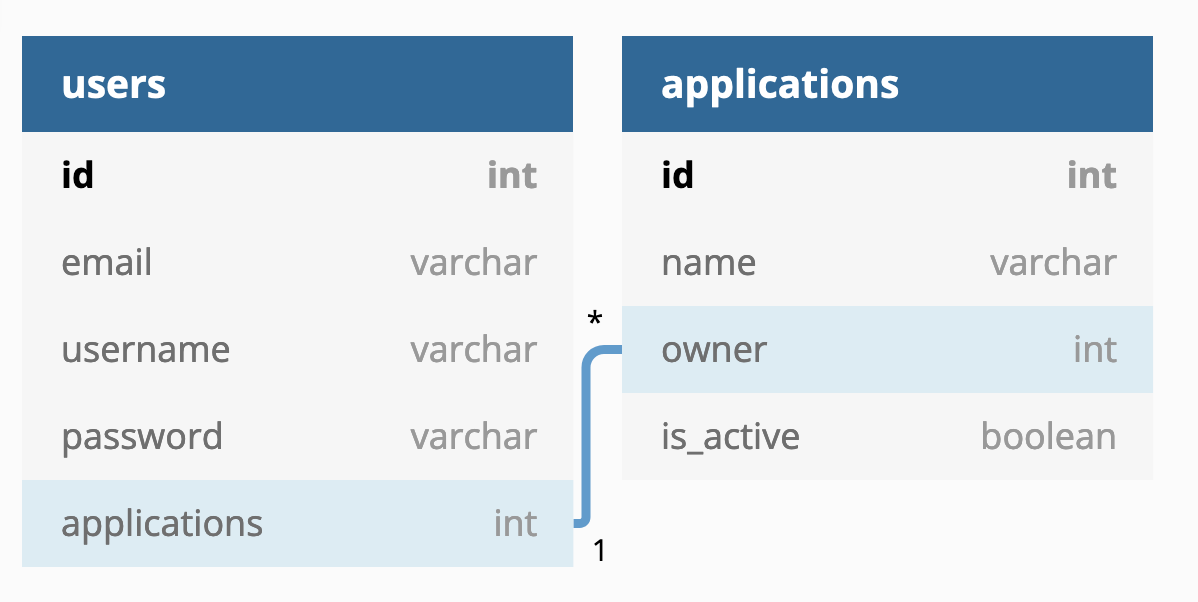
Our model is slightly basic for this example: We have users with some classic fields (id, email, username, password), and users can create projects within the Escape SaaS. These projects are named Applications within our code.
Users have many applications, and here is the resulting SQL relational graph:
First resolver
In GraphQL, the queries are handled by resolver functions. In NestJS, we will implement such a function in a class-based style enforced by the framework.
The following code defines two things:
- A query getUser for retrieving a User from the database
- A mutation createUser for creating a new User in the database
Note: The PrismaService used here is taken from the NestJS documentation
@Resolver(() => UserObjectType)
@Injectable()
export class UserResolver {
constructor(private readonly prismaService: PrismaService) {}
@Query(() => UserObjectType)
async getUser(
@Args('id', { nullable: false })
email: string
) {
return this.prisma.user.findUnique({
where: { id }
}); // This code is related to Prisma and may vary with your ORM
}
@Mutation(() => UserObjectType)
async createUser(
@Args('UserCreateInput', { nullable: false })
createUserInput: CreateUserInput
) {
const password: string = await bcrypt.hash(createUserInput.password, 10);
return await this.prisma.user.create({
data: {
...createUserInput,
password,
}
}); // This code is related to Prisma and may vary with your ORM
}
}
With this, we can perform GraphQL queries to the API like this one:
mutation {
createUser(
UserCreateInput: {
email: "new-guy@escape.tech"
password: "j;vs?xsblk"
username: "maxence"
}
) {
id
email
applications {id scans {alerts {id}}}
}
}Results Serialization
Wikipedia: In computing, serialization is translating a data structure or object state into a format that can be stored or transmitted.
Serialization (especially specifying which field can be queried and which can not) is automatically handled by the framework by specifying the returned type of a Query.
This is why we define separate object types for both users and applications, which will be the returned types of our resolvers.
@ObjectType()
export class UserObjectType {
@Field()
id: string;
@Field()
email: string;
@Field()
username: string;
// this is new
@Field(() => [ApplicationObjectType], { nullable: false })
applications: ApplicationObjectType;
}One can notice here that the password field is excluded from the UserObjectType class, so one can not query it from the getUser query.
query {
getUser(id: 1) {
id
email
password // This will result in an error
}
}Handling SQL relationships
Adding a relational field returned by the API
The applications are queried in a separate SQL query. To achieve this, we declare an application field in our UserObjectType class.
@ObjectType()
export class UserObjectType {
@Field()
id: string;
@Field()
email: string;
@Field()
username: string;
// this is new
@Field(() => [ApplicationObjectType], { nullable: false })
applications: ApplicationObjectType;
}
@ResolveField(() => [ApplicationObjectType])
async applications(@Parent() user: User) {
return await this.prisma.application.findMany({
where: { ownerId: user.id }
});;
}When a query asks for the applications field of a user returned by getUser, the resolver defined in UserObjectType.applications is executed. This is because we annotated it with the @ResolveField directive.
We can now query a user's applications:
query {
getUser(id: 1) {
id
email
applications {
id
name
}
}
}Querying dynamic fields
Since the @ResolveField decorator enables us to create a custom resolver function, we can use it to return computed data.
For instance, for a given user, we might want to count its applications or active applications. To do so, we need to:
- Update the UserObjectType model to declare the dynamic fields that it can return
- Update the UserResolver class to implement the two dynamic resolvers
@ObjectType()
export class UserObjectType {
@Field()
id: string;
@Field()
email: string;
@Field()
username: string;
@Field(() => [ApplicationObjectType], { nullable: false })
applications: ApplicationObjectType;
@Field()
applicationsCount: number;
@Field()
activeApplicationsCount: number;
}
@ResolveField(() => number)
async applicationsCount(@Parent() user: User) {
return await this.prisma.application.aggregate({
where: {
ownerId: user.id
},
_count: true
});
}
@ResolveField(() => number)
async activeApplicationsCount(@Parent() user: User) {
return await this.prisma.application.aggregate({
where: {
ownerId: user.id,
isActive: true
},
_count: true
});
}
We can now query these fields like so:
query {
getUser(id: 1) {
id
email
applicationsCount
activeApplicationsCount
}
}Writing field functions
With this directive, we define functions that can use the same directives and decorators as the classic query resolvers. This means we can use the @Arg directive and make a single parametric resolver for these two fields.
@ResolveField(() => number)
async applicationsCount(
@Parent() user: User,
@Args('isActive', { nullable: true }) isActive: boolean
) {
const isActiveWhereStatement = isActive ? {} : { isActive: true }
return await this.prisma.application.aggregate({
where: {
ownerId: user.id,
...isActiveWhereStatement
},
_count: true
});
}And then, we can perform the similar query:
query {
getUser(id: 1) {
id
email
allApplicationsCount: applicationsCount
activeApplicationsCount: applicationsCount(isActive: true)
}
}
The Prisma n+1 problem
Per the Prisma documentation:
The n+1 problem occurs when you loop through the results of a query and perform one additional query per result, resulting in n a number of queries plus the original (n+1). This is a common problem with ORMs, particularly in combination with GraphQL, because it is not always immediately obvious that your code is generating inefficient queries.This part is already well documented by Prisma itself, so we will not do a lot more than apply their advice on our specific problem here.
When we query a user with the getUser query, we can ask to retrieve its applications using a dedicated applications field resolver. When we only query one user, everything is fine, and we run the application resolver at most once.
If we make multiple queries for the users, for some admin panel, we will have a query getUsers able to retrieve multiple users.
query {
getUsers() {
id
email
applications {
id
name
}
}
}However, such a query will call the applications resolver once per retrieved user, leading to n additional queries.
To solve this issue, we will have to replace our findMany Prisma calls with the fluent API provided by the ORM. The difference here between findMany and <x>.applications() calls is that Prisma can batch even between multiple resolvers calls.
@ResolveField(() => [ApplicationObjectType])
async applications(@Parent() user: User) {
return this.prisma.user.findUnique({
where: { id: user.id },
})
.applications()
}Conclusion
This article was about how we arranged several technologies and frameworks (GraphQL, NestJs, Prisma) together to build up our backend infrastructure. Some of the principles explained here are guidelines for our development team.
We used a very simplistic example to illustrate this article. However, if you love contributing to complex applications and desire to be involved in developing such systems, from design to deployment, you might want to join the Escape team!
💡 Want to learn more about GraphQL APIs security? Take a look at our articles below: