Benchmarking AI Pentesting Tools: A Practical Comparison
We benchmarked 4 AI pentesting tools: Escape, Shannon, Strix, and PentAGI against a modern vulnerable application. Learn more about their detection rates, false positive rates, and scanning speed.


Agentic pentesting isn't just another flavor of scanner. The pitch is that these tools can infer API structure, poke around undocumented endpoints, and validate findings through real exploitation, not just flag SQL injection and walk away. That's a meaningfully different promise from anything we've had before.
And the market has exploded in 2026. Dozens of agentic pentesting tools now claim "autonomous pentesting", and honestly, the claims are running well ahead of the evidence.
We've talked to plenty of security teams trying to figure out what's worth the budget and what's mostly marketing, and we've often heard that they'd like to see benchmarks for applications with complex business logic scenarios that resemble real-life web apps. Not only from a "what a tool can find" standpoint, but also how efficient is it in finding? What's the false positive rate that a security engineer would eventually have to spend (hopefully not) hours triaging?
So we built one. As we previously built both of our DAST benchmarks (for REST & GraphQL APIs, for web apps - Gin & Juice Shop)
Four tools - commercial and open source. One vulnerable target.
We ran every tool under identical grey-box conditions, tracked where each one found vulnerabilities and where it whiffed, and tried to draw conclusions that are useful if you're picking a tool, not if you're writing a social media post to build the most hype around.
TL;DR
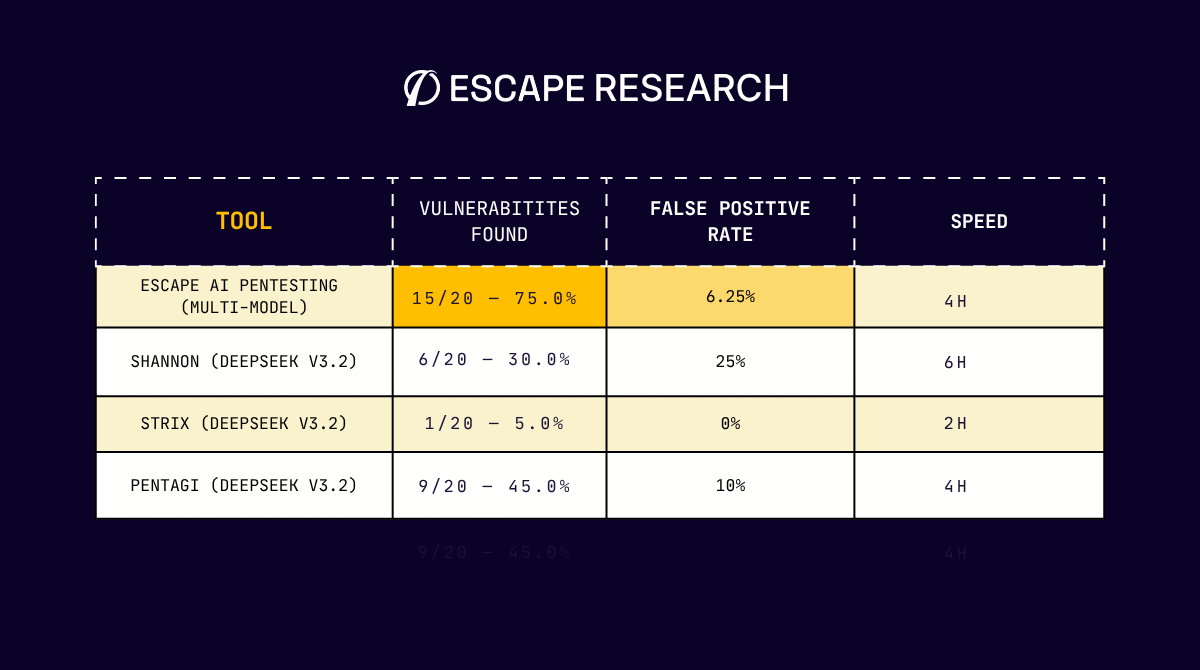
- We compared four tools - commercial and open source (Escape, Shannon, Strix, PentAGI) tested across a vulnerable web app Duck Store (20 vulnerabilities, including business logic scenarios, modern FastAPI + React stack).
- Using a vulnerable application helped us to know by default that the vulnerability was exploitable (reducing the time to manually verify the finding by our research team)
- Grey-box conditions: each tool received the target URL, OpenAPI spec, and credentials. We haven't given access to the source code (except Shannon, which requested it - something to keep in mind)
- Shannon, Strix, and PentAGI are based on DeepSeek v3.2. The three DeepSeek tools diverge widely on Duck Store (6/20 vs 9/20 vs 1/20) despite sharing the same model. The key variable is how each tool structures the agent's action loop, manages tool calls, and handles authentication. When evaluating agentic pentesting tools, the model card can be a secondary concern. Evaluate the orchestration layer first.
- Only Escape found the Unauthenticated Testimonials Update through spec-level access control analysis. It was a finding every other tool missed.
- Detection rate represents confirmed exploits only; a finding counts only when the agent demonstrates actual exploitation
You can jump into our methodology and more detailed findings and analysis below.
Methodology
Target application selected and why
We selected Duck Store, a deliberately vulnerable web application, that contains business logic flaws from the web interface to the API, including chaining possibilities. It was built on a modern stack: React on the frontend, FastAPI on the backend.
Vulnerability categories tested
A broad range of vulnerability classes was covered, mapped to OWASP Top 10 and beyond:
- Injection — SQL injection, SSRF, SSTI
- Broken authentication — JWT algorithm confusion, 2FA bypass, weak credentials, session fixation, no rate limiting
- Broken access control — IDOR, broken object-level authorization, admin endpoint exposure, mass assignment
- XSS — Stored, reflected, DOM-based, HTTP header injection
- Business logic flaws — negative quantities, coupon abuse, discount manipulation, referral fraud, shipping bypass
- Information disclosure — user enumeration
- Miscellaneous — open redirect
Evaluation metrics
The primary metric is detection rate: confirmed findings (true positives) divided by total known vulnerabilities. A finding is counted only when the agent demonstrates actual exploitation or a clear, reproducible proof of concept.
Secondary metrics tracked:
- Total run duration per tool per target
- False positive rate — flags raised for non-existent vulnerabilities, as a percentage of total HIGH/MEDIUM findings.
- Unique findings — vulnerabilities detected by only one tool in the set
Test environment & conditions
Tests were run in grey-box conditions: each tool received the target URL, a pointer to the API documentation (/openapi.json), the available API surface (/api/), and a set of default credentials. One exception: Shannon requested access to the application source code as part of its analysis, which was provided. All other tools operated without source code access.
Both applications ran locally in Docker. Each tool was run once per target; results were not averaged across multiple runs.
Reproducibility & fairness constraints
To keep conditions consistent across tools:
- All tools received the same information in the form that their configuration expected
- No tool-specific tuning was performed beyond what each tool's documentation recommends
AI pentesting tool selection for benchmark
We selected AI pentesting tools that represent meaningfully different points in the design space: different underlying models, different levels of autonomy, different configuration paradigms, and different target audiences. The goal was not to pick the most well-known names, but to stress-test how architectural and model choices translate into real-world detection rates.
Here is the full list:
Escape — commercial agentic pentesting platform with a proprietary built model.
Shannon — AI pentester developed by Keygraph and available as Lite - Local testing (reconnaissance, parallel vulnerability analysis, parallel exploitation, reporting) and commercial (which allows connecting to Lite as part of ASPM). We ran it on DeepSeek v3.2. Shannon's distinguishing feature is a structured YAML configuration layer that lets operators define authentication flows, scope rules (focus/avoid), and session preservation constraints before the agent starts. This gives practitioners fine-grained control over what the agent explores.
Strix — open-source agentic pentesting tool. We ran Strix on DeepSeek v3.2. Strix takes a simpler configuration approach: a target URL plus a free-form instruction string. Less structured than Shannon, closer to a guided reasoning agent with pentesting tooling.
PentAGI — open-source agentic pentesting framework. For benchmark, we run it on DeepSeek v3.2. PentAGI runs in a containerized environment; for Duck Store, the agent accessed the application via its Docker network hostname rather than localhost. Configuration is prompt-only, with no structured scope or authentication configuration.
Setup & configuration
All tools received the same core information: the target URL, a pointer to the OpenAPI spec (/openapi.json) and two credential pairs (admin / admin, user / password). Shannon additionally received access to the application source code, as requested by the tool. The exact prompt or configuration varied by tool to match each tool's expected input format, using a free-form prompt where the tool expects one, and a structured config where required.
Escape was configured and run via its commercial platform interface. No configuration file is published.
Strix was invoked with the following instruction file and run via the uv run strix --target http://localhost/ --config config.json --instruction-file instruction.txt --non-interactive:
Perform a comprehensive penetration test of the Duck Store web application at http://localhost/.
The application is an e-commerce platform with a FastAPI backend and React frontend. It has a REST API documented at http://localhost/openapi.json.
Default credentials to use as starting point:
admin / admin
user / password
PentAGI was invoked with the same instructions.
Shannon was the most configuration-rich tool. Its YAML config specified an explicit login flow (field-by-field), focus paths (/api/*, /admin/*), and an avoid rule to skip /logout and preserve the session:
authentication:
login_type: form
login_url: "http://localhost/login"
credentials: { username: admin, password: admin }
login_flow:
- "Type $username into the username field"
- "Type $password into the password field"
- "Click the 'Login' (or 'Sign In') button"
success_condition:
type: url_contains
value: "/dashboard"
rules:
focus:
- { description: "Focus on API endpoints", type: path, url_path: "/api/*" }
- { description: "Focus on admin endpoints", type: path, url_path: "/admin/*" }
avoid:
- { description: "Skip logout functionality", type: path, url_path: "/logout" }Results
Results below reflect confirmed findings only. A vulnerability counts as found only when the tool demonstrates actual exploitation or clear proof of concept.
| Tool | Duck Store Found | Duck Store Score | Duck Store Duration | Duck Store FP Rate |
|---|---|---|---|---|
| Escape (multi-model) | 15 | 75.0% | 4h | 6.25% |
| Pentagi (DeepSeek v3.2) | 9 | 45.0% | 4h | 10.00% |
| Shannon (DeepSeek v3.2) | 6 | 30.0% | 6h | 25% |
| Strix (DeepSeek v3.2) | 1 | 5.0% | 2h | 0% |
Below is a summary by vulnerability category for the Duck Store target:
| Category | Escape | Shannon | Strix | Pentagi |
|---|---|---|---|---|
| Injections | ✓ | ✓ | ✓ | ✓ |
| SSRF | ✓ | ✓ | ✗ | ≅ 50% |
| XSS | ✓ | ✓ | ✗ | ✗ |
| IDOR | ✓ | ✗ | ✗ | ✓ |
| Business logic | 75% | ✗ | ✗ | 75% |
| Access control | 75% | ✗ | ✗ | 25% |
| Authentication flaws | 25% | ≅ 50% | ✗ | 25% |
| Information Disclosure | ✓ | ✗ | ✗ | ✗ |
| Misc (Open Redirect) | ✓ | ✗ | ✗ | ✗ |
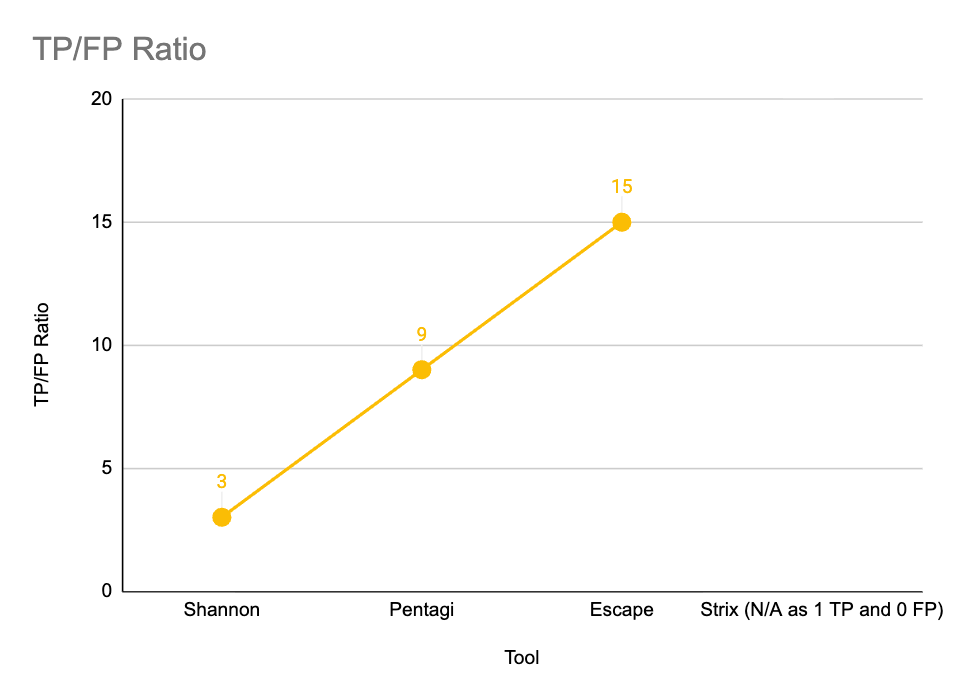
The TP/FP ratio measures detection precision, what it means is that a higher value indicates fewer false positives relative to confirmed vulnerabilities:
Highlights
Escape leads overall.
With 15/20 (75.0%) on Duck Store, Escape comes out on top. It leads Pentagi (15/20 vs 9/20) and has the highest count of unique findings: 3 Duck Store vulnerabilities detected by no other tool.
Shannon and Strix are effectively identical in their model — but not in results.
Both share the same underlying model (DeepSeek v3.2). On Duck Store, Shannon finds 6/20 (30.0%), Strix finds 1/20 (5.0%), and Shannon took 6h for those 6 findings. Same model, very different scaffolding, still weak results on Duck Store.
Pentagi struggles.
At 45.0% on Duck Store, Pentagi's composition reveals a narrow profile: strong on injection and IDOR, missing XSS and access control entirely.
Finding walkthroughs
Numbers tell part of the story. Below are two concrete findings from opposite ends of the detection spectrum — one caught by a single tool, one caught by all five — and how the exploitation chain was built.
Unauthenticated modification of testimonials (Duck Store — Escape only)
Severity: HIGH | Category: Broken Access Control | Found by: Escape only
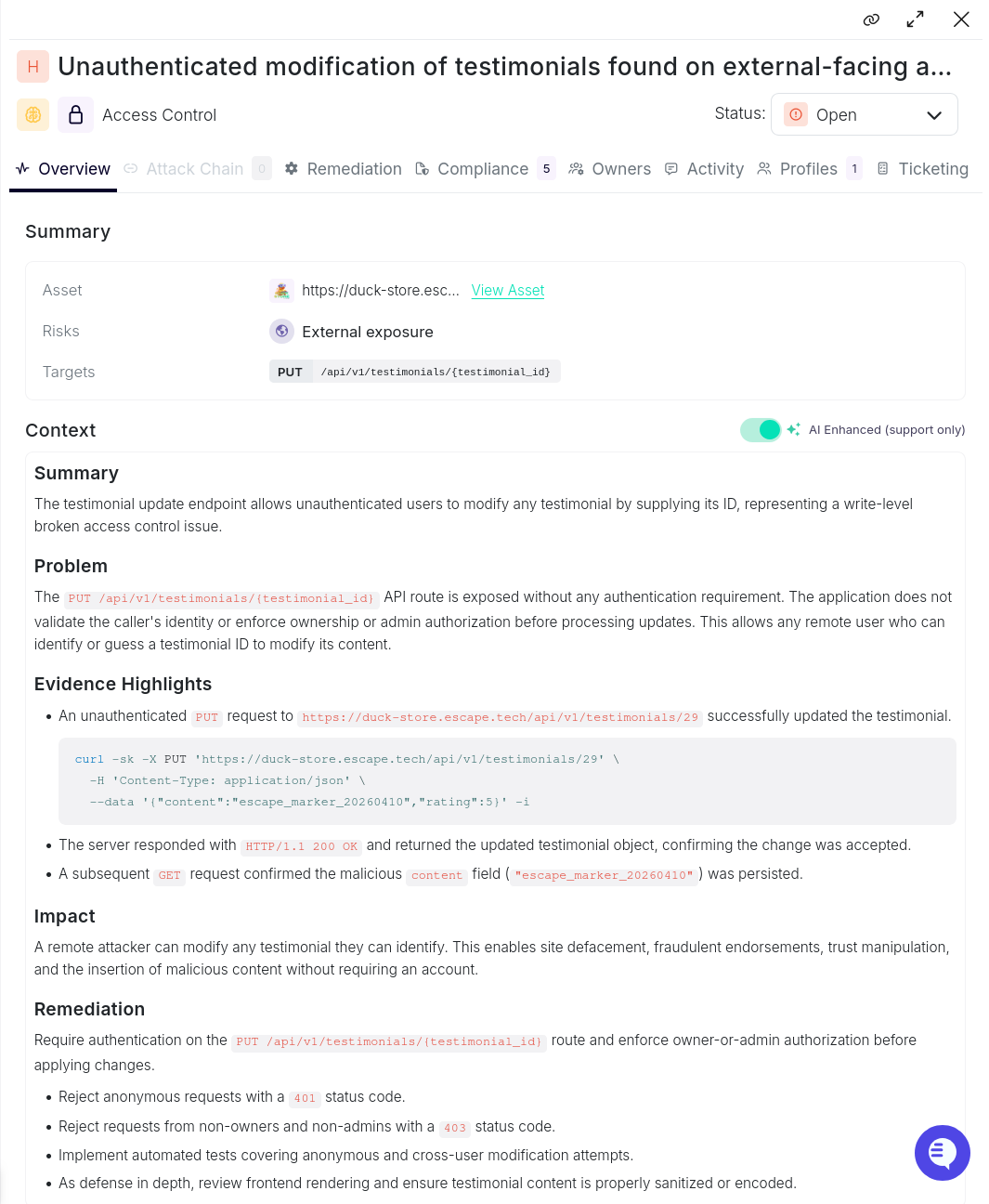
The Duck Store allows users to submit testimonials. The POST /api/v1/testimonials/ route is authenticated. The PUT /api/v1/testimonials/{id} update route is not. No authentication, no ownership check, no authorization of any kind.
Escape's agent noticed the discrepancy between the creation and update routes in the OpenAPI spec, probed the update endpoint without credentials, and confirmed the write succeeded:
curl -sk -X PUT 'https://duck-store.escape.tech/api/v1/testimonials/29' \
-H 'Content-Type: application/json' \
--data '{"content":"escape_marker_20260410","rating":5}'HTTP/1.1 200 OK
{
"id": 29,
"content": "escape_marker_20260410",
"rating": 5
}A follow-up GET confirmed the change persisted. Any unauthenticated user who can enumerate a testimonial ID can overwrite its content — enabling defacement, fraudulent endorsements, or injection of malicious content into a surface rendered to all visitors.
No other tool flagged this. The four others either did not probe the update route without credentials or did not connect the authentication gap in the spec to an exploitable write path.
Unauthenticated SQL Injection in product filter (Duck Store)
Severity: HIGH | Category: Injection
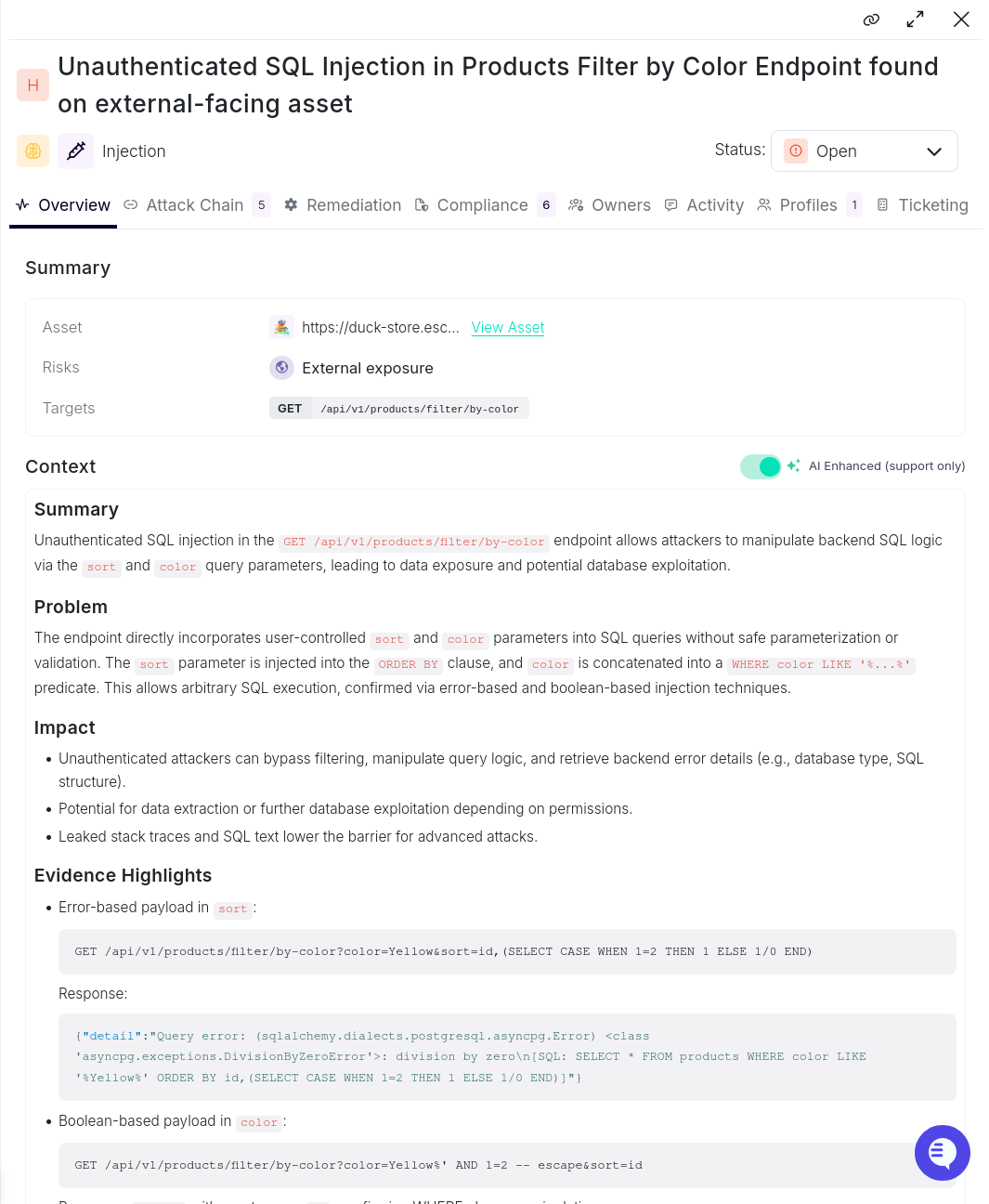
The product filter endpoint (GET /api/v1/products/filter/by-color) accepts color and sort query parameters with no authentication required. Escape's agent worked through a four-step chain to confirm full exploitation:
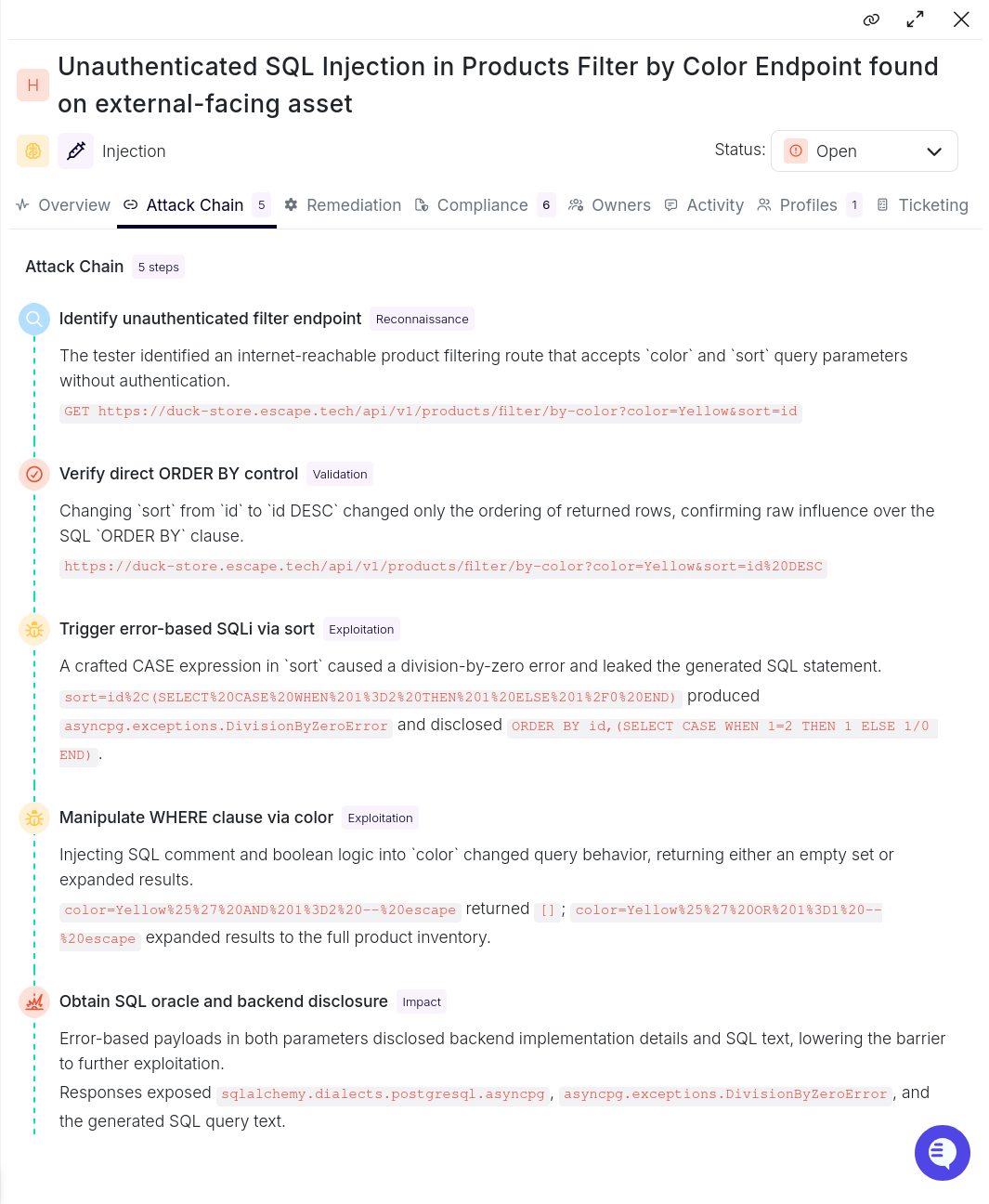
Step 1 — Reconnaissance: The agent identified the endpoint as unauthenticated and externally reachable from the OpenAPI spec.
Step 2 — Validation: Changing sort=id to sort=id DESC altered row ordering, confirming direct influence over the SQL ORDER BY clause.1
Step 3 — Error-based exploitation: A crafted CASE expression in sort triggered a division-by-zero error that leaked the generated SQL statement:
asyncpg.exceptions.DivisionByZeroErrorcolor=Yellow%' AND 1=2 -- escape → [] (empty result)
color=Yellow%' OR 1=1 -- escape → full product inventoryThe error responses also disclosed the ORM stack (sqlalchemy.dialects.postgresql.asyncpg), lowering the barrier to further exploitation.
Shannon was the only tool that did not find this. All 3 others identified the injection, demonstrating it is well within reach of current tooling when the surface is unauthenticated, and the parameter is directly interpolated into SQL.
Analysis
Model choice vs. agentic architecture
All three DeepSeek tools share the same model yet diverge on Duck Store. Shannon finds 6/20, Pentagi finds 9/20, Strix finds 1/20. The model is constant — the variable is how each tool structures the agent's action loop, manages tool calls, and handles authentication.
Shannon's explicit login flow and focus/avoid rules keep the agent on productive paths and preserve session state. Pentagi's minimal prompt leaves more to the model's discretion. Strix ran for 2 hours and returned a single confirmed finding — its structured instruction approach did not translate to Duck Store's authenticated API surface.
This has a practical implication: when evaluating agentic pentesting tools, the model card is a secondary concern. Evaluate the orchestration layer first.
The context advantage
Escape (15/20) leads on Duck Store by bringing a broader toolset and accumulated patterns across many application types. Escape found the Unauthenticated Testimonials Update through spec-level access control analysis — a finding every other tool missed.
The pattern is consistent: on structured, API-first targets, context-aware reasoning is sufficient to match specialized tooling. Purpose-built coverage retains an edge where domain-specific tuning and curated payload libraries can be applied.
Limitations of this benchmark
What this benchmark does not measure
Remediation quality: Tools varied significantly in how they described and contextualized findings. We did not score remediation guidance quality in this benchmark.
Multi-run variance: Each tool was run once per target. Agentic systems can produce different results across runs due to non-determinism in the model. A single run is sufficient for a directional comparison but not for establishing reliability bounds.
Real-world applications: Target is a deliberately vulnerable test application. Detection rates on production systems — with WAFs, rate limiting, complex session management, and mixed authentication schemes — would likely be lower and differently distributed across tools.
Time-to-finding and exploit quality: We measured the detection rate only. A tool that finds 10 vulnerabilities in 1 hour with high-confidence reproduction steps is more valuable than one that finds in 4 hours with ambiguous output, even if their raw scores are identical.
Known biases and constraints
Single-run results: Non-determinism in agentic systems means our results are a point estimate, not a distribution. Tools that perform well on average might have high variance; a single run may not represent typical performance.
What security engineers should take away
We hope this benchmark gives you a grounded view of how agentic pentesting tools actually perform on modern web applications. Our goal was to be transparent about both their capabilities and their limits, including the models powering them. We welcome feedback on how to make this review sharper.
The key takeaway: evaluating AI pentesting tools (or any security scanner) means asking two questions, not one. "How much did the tool miss?" matters, but so does "How noisy is the tool?" A scanner that finds everything but buries you in false positives isn't actually helping your team. Signal-to-noise is the difference between a tool engineers trust and one they tune out.
It's also worth remembering that findings are only a small part of the problem at scale. For most large organizations, the real bottleneck isn't detection. We all know it's the engineering process around remediation. Security engineers are builders, and they need tools that fit into how they actually work.
That's why we're releasing a one-click OAuth 2.1 integration that connects Escape to Claude Desktop, Claude.ai, and Claude Code. Once connected, the entire Escape platform is reachable from your prompts: discover crown-jewel assets with ASM, run human-grade pentests, triage findings, and hand developers clean remediation guidance, all without leaving the assistant. You can learn more about it in the following webinar.
What’s next
Last year, we researched vulnerabilities in apps built on AI platforms like Lovable. In the next round, we'll extend that work to compare apps built with those platforms against apps built with Claude Code — and evaluate how both DAST and AI pentesting perform against a set of AI-generated apps with real business logic vulnerabilities. Because let's be honest: your marketers and engineers are going to vibe-code even more in 2026, and that surface area isn't going away.
And if you're looking to scale your automated penetration testing without compromising on quality on modern apps, request a demo, and we'll show how Escape can fit into your engineering workflows.