Feedback Driven API exploration at the service of GraphQL Security

Introduction
Automating the audit of APIs is a very hard problem: we want to dynamically evaluate those APIs' security, performance, and reliability.
But APIs take parameters that are tightly coupled to the underlying business logic. We need a way to know what sequences of requests to send, with what parameters, and in which order to have maximum API coverage to improve the scan quality.
A naive automated would also not work: putting random data in parameters would likely not pass the API's validation layer, thus giving us little insight into the real API behavior.
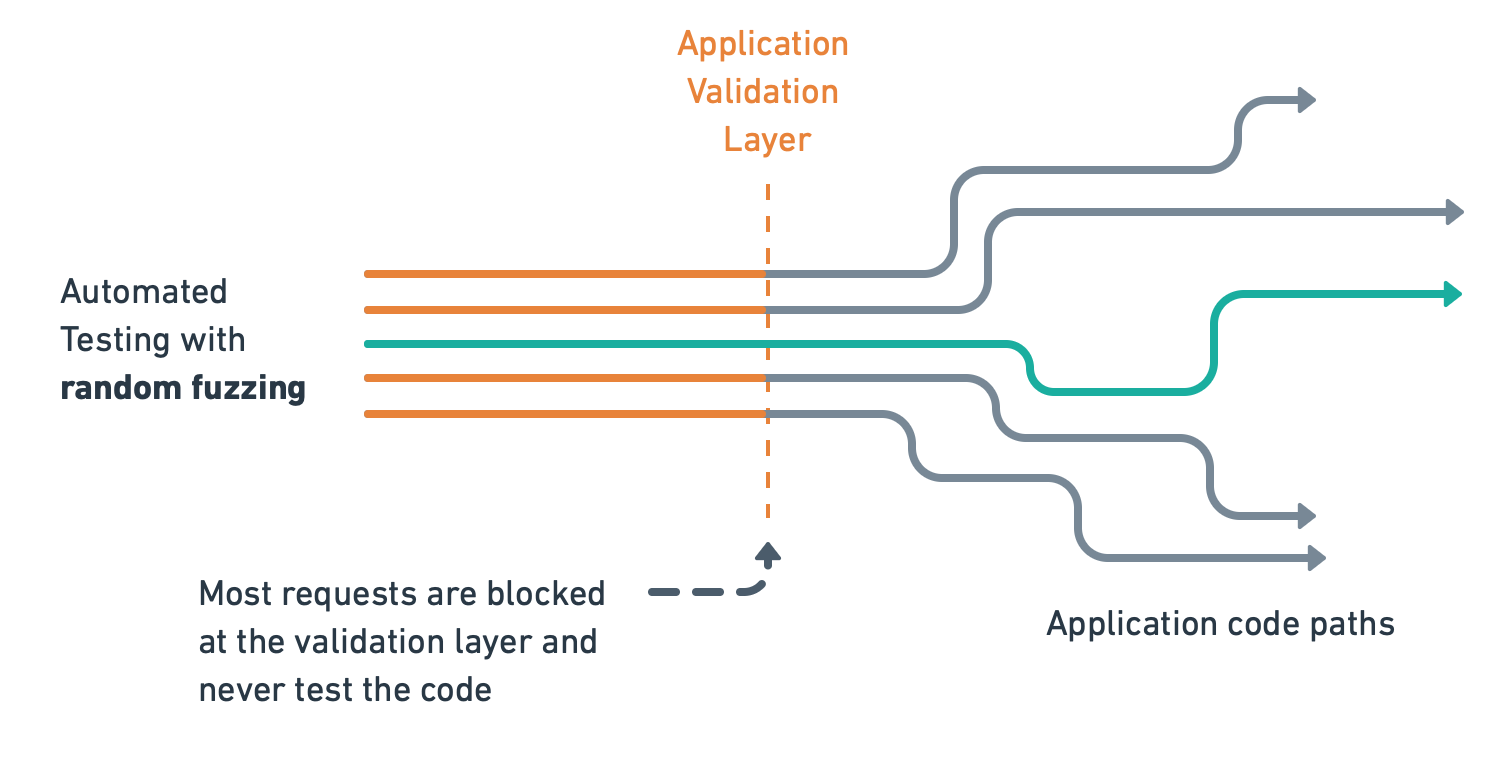
Manually creating tests for each API is also not sustainable: it would take years for our 10-people team. We needed to do it in an automated way. Fortunately, our main R&D efforts at Escape aimed to generate legitimate traffic against any API efficiently.
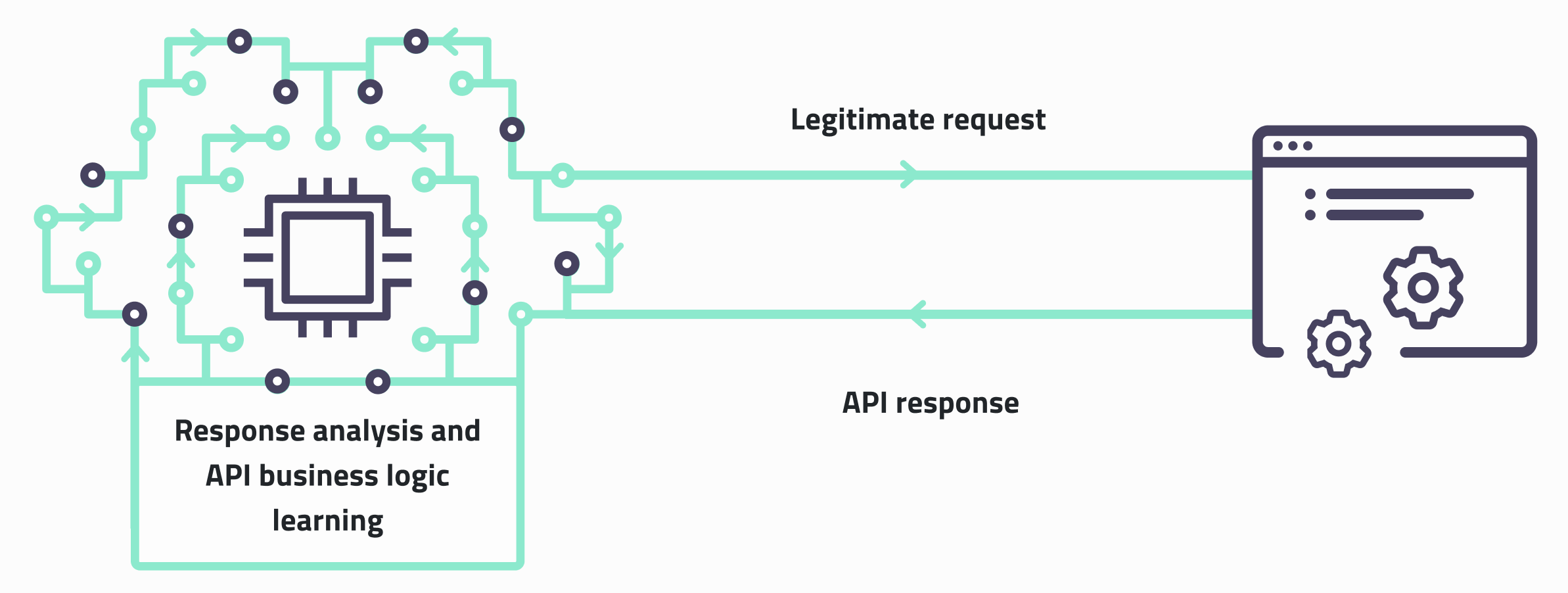
That's how we developed Feedback-Driven API Exploration, a new technique that quickly asses the underlying business logic of an API by analyzing responses and dependencies between requests.
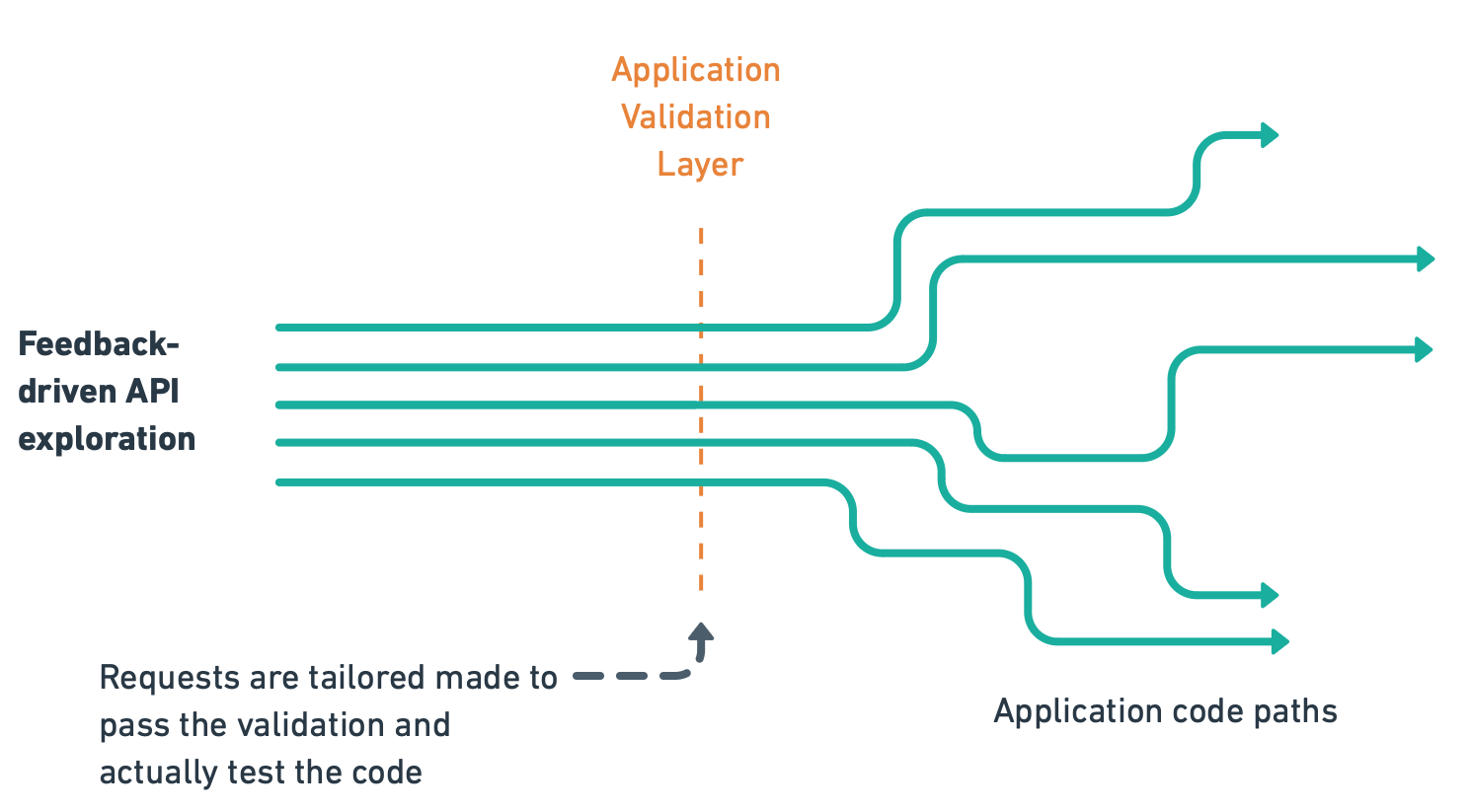
The global idea is to prioritize requests by inferring which answer may allow sending which requests. The program should also analyze the responses to have more coherent requests until you are satisfied with the results.
Some technologies exist for restful APIs, such as REST-ler or BackREST. But for GraphQL APIs, not so much. Today we will explore how the Escape research team (myself included ;) ) managed to implement the first feedback-driven GraphQL API exploration.
By nature, GraphQL APIs are complex:
- Multiple different requests can reach the same object
- Complexe arguments with InputObject
- Requests can be very precise and
- Listing all requests is not an option with significant introspection
The algorithm
Now let's get to the heart of this article. As our example, we will use a slightly modified version of the Damn Vulnerable GraphQL Application's introspection. GraphQL voyager visualizes the introspection (a great tool, check it out if you don't know it yet).
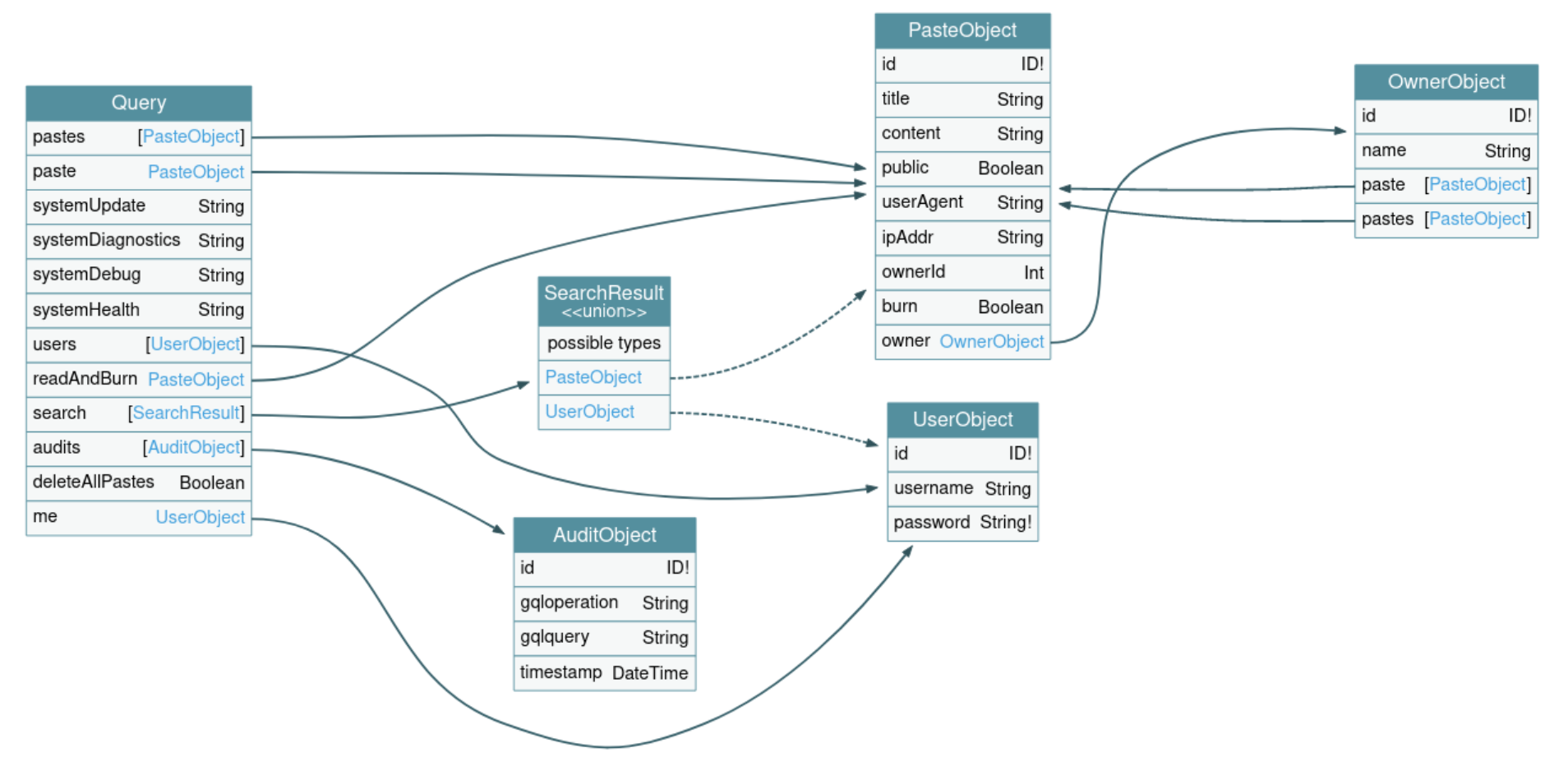
The first step is similar to what's already done with restful API; we want to find the source of every argument in the introspection. In our example, we want to match the arguments id and title from the query paste to the fields id and title from the object PasteObject. Here we use a lot of inference with some natural language processing, but that's a subject for another day. We will call the introspection with the sources of the arguments the augmented introspection.
From the augmented introspection, we will create an Oracle that will give us the following request to send. The state of Oracle will be updated with each request we send.
As said previously, because a request is a path in a graph, we cannot expect to send every possible one. We need a way to construct a satisfying subset of requests. With a simple rule, we can eliminate most of the requests. Let's say we have request A and request B. If the information needed to send A (the arguments of A) is the same as the one to send B and the information provided by A is a subset of the one provided by B, then we can remove A from our subset.
Example:
query {
pastes{
id
}
}
query {
pastes{
id
title
}
}
On DVGA, we want the Oracle to give us the following requests:
- systemUpdate
- systemHealth
- pastes{...}
Now that we have defined what we expect of the Oracle, let's build it.
We have defined a request as an object that needs information on some objects to be sent and that returns information on other or the same objects. We can implement this in an oriented bipartite graph, one type of node being the requests and the other being the objects of the GraphQL introspection. We can attribute a score to the objects as a measure of how well it is known and a score to the requests as a measure of how easy it is to send, given the score of the objects.
Once we have that graph, it is simply a matter of choosing the requests with the highest score and updating the graph.
This approach allows us at Escape to improve the quality of the exploration of GraphQL API and the number of requests needed to get a satisfying result.

Food for thoughts
💡 Wanna learn about GraphQL testing? Read our blog article "How to test your GraphQL API?".