Introducing Cascade: the multi-agent penetration testing that becomes an expert in your business
Escape CASCADE allows you to run deep, human-grade assessments across your whole attack surface, proves every finding with a working exploit, and gets more expert in your business with every engagement.




Most automated pentesting tools treat your application like a stranger. It shows up, runs a bunch of tests against whatever endpoint it's pointed at, and leaves a report. It doesn't know that your "admin" can act on behalf of a "doctor," that a "patient" should never see another patient's records, or that your pricing logic lives across three services that only break when you test them together.
Cascade is different. It's the multi-agent pentest engine inside Escape, and because it sits on top of everything the platform already knows about your attack surface, it doesn't start from zero. It starts as something closer to an in-house pentester who has read your docs, mapped your APIs, and watched your last ten releases. Every engagement makes it more expert in your business. Every finding it proves becomes a test your DAST can re-run forever.
This is the deep-assessment layer of an offensive security program, built to run continuously inside the engineering processes, not as a yearly one-off cost.
Why we changed the approach
Over the last two years, automated pentesting got faster, cheaper, and, thanks to frontier AI, genuinely deeper. Agents can now reason about an application the way a tester does, chain multi-step exploits, and find logic flaws that traditional vulnerability scanning never could. That's real progress, and the whole industry is better for it.
But almost all of it still optimizes for the same deliverable: a pentest report. Point a tool at a target, get a PDF, satisfy the compliance requirement. The test arrives knowing nothing about your org, runs once, and leaves nothing behind.
A report is not a program. The security teams we work with don't need another document sitting in a backlog. They need offensive security that runs the way engineering runs. Yes, continuous, contextual, and compounding.
The hard part has always been running a test that understands your application well enough to find the vulnerabilities that only exist because of how you built it. Business logic. Privilege escalation across user roles. The findings a good human pentester gets to in week three, not the ones a generic scanner gets in the first hour.
So the gap we set out to close was never just depth. The gap was context and continuity.
Our research team at Escape rebuilt our pentesting engine around two ideas:
- First: an autonomous test is only as good as its context, so we give it the full picture of your attack surface.
- Second: depth and scale aren't a trade-off if the engine that finds the vulnerability hands it to a system that can re-test it on every release.
That's Cascade, and it's why it lives next to ASM and DAST instead of off to the side.
What makes Cascade different
It becomes an expert in your business
Cascade runs on the same platform as Escape ASM and DAST, so it starts every engagement with a continuous model of your entire attack surface: every API, SPA, and host discovery has been found, and everything DAST already covers. It can also integrate with your existing security, cloud, and developer tools to sharpen the picture and adapt its tests to how your systems actually work.
So a Cascade engagement isn't an isolated test. It compounds. Our updated architecture allows us to keep a memory of what's relevant to you across engagements. For example, that you work in healthcare and have admin, doctor, and patient roles with different access levels, that your docs contain real-looking data, that one service handles payments. The more Cascade tests, the more it knows. That's the part a transactional tool can't replicate: it has no reason to remember your application tomorrow.
It tests as multiple users at once
Cascade holds several user identities at the same time, each in its own isolated browser session. That's the only way to answer "can user A read user B's order?" and it's how broken object-level authorization and privilege escalation become findable. Single-identity scanners structurally can't ask that question. We built Cascade around it.
Your entire attack surface is assessed
Most AI pentesting tools focus on exploitation, but the best exploit agent is useless if it misses half your application. Coverage is what separates a real security assessment from a lucky scan.
Cascade builds on years of DAST expertise to solve this at the root. A dedicated discovery agent systematically maps your entire scope before exploitation begins, feeding everything back into the platform context so no endpoint, page, or asset is left untested. During the exploitation phase, coverage gaps are actively monitored and closed in real time.
And unlike black-box tools that leave you guessing what was actually tested, Cascade makes coverage fully auditable: every API endpoint, webpage, and asset discovered is surfaced in the results, so you can see exactly what was assessed, and confidently attest to it.
Every finding is proven, then re-tested forever
A finding without a working exploit is a guess. Every Cascade finding ships with the proof: the exact request sequence, the user scopes involved, the working exploit, and framework-specific remediation guidance.
Then it stops being a one-time result. Findings flow into Escape DAST, so what Cascade proves once becomes an unlimited regression test. It re-runs on every release, inside your CI/CD. Run the deep assessment once. Keep the coverage forever. Cascade brings the creativity and depth; DAST brings the scale. That combination is the whole point.
How Cascade works

Cascade is a multi-agent harness with an orchestrator at the center. It replaces the earlier model of separate, single-purpose agents (one each for XSS, SQLi, IDOR, and so on). Instead of a fixed agent list, Cascade creates the specialists a target actually needs, on demand. And Cascade agents don't carry one giant prompt. They load modular skills: focused playbooks, scoped to the task in front of them, so each agent's context stays small and relevant.
Powered by Attack Surface Management knowledge: Cascade doesn't start from a blank page, it starts from everything the platform already knows. When Escape ASM discovers an asset, it fingerprints it (say, a Next.js app behind Cloudflare on AWS, using Auth0) and hands Cascade the full context: the URL, the linked API services, schemas, tech stack, and scope rules. Then the orchestrator starts by modeling your application: it crawls the app, learns its business logic, and maps the APIs behind it.
Coordinated, agentic exploitation: Now the orchestrator has a working model of the app, and that's what it attacks. It holds the state of the engagement and decides what to test next. Beneath it, agents do the work a pentest team would: recon, gaining access, probing business logic, exploiting. Each with the tooling a human reaches for, like a service to test for SSRF or a mailbox to verify emails.
In a nutshell, the Cascade harness is built from four roles:
- Orchestrator: plans the engagement, breaks it into tasks, spawns other agents, and decides when the engagement is complete. It coordinates the swarm and prioritizes work within the configured scope, users, context, and time budget.
- Coverage agent: an agent that explores the surfaces and plays the role of an advisory auditor that proposes follow-up work from coverage gaps. It has no exploitation tools of its own.
- Exploitation agents: focused agents the orchestrator creates for a specific job (for example "SQLi discovery on the reporting API", "XSS validation", "auth testing across tenants"). These agents are created dynamically and run in parallel; once an agent’s task returns, it stops consuming budget.
- Reporter agent: receives candidate findings from exploitation agents and independently reproduces each one on the live target, collecting its own evidence before filing an issue. The reporter is deliberately isolated from exploitation agent-to-exploitation agent messaging so its verification stays independent.
Exploitation agents coordinate through a shared message bus (seeded with topics such as recon, xss, sqli, idor, ssrf, auth, and rce) and a shared knowledge store, so signal discovered by one agent reaches the rest of the swarm quickly.
Context flows back through the orchestrator after every step, and one agent's discovery shapes what the next one tries.
And when Cascade finds something, it proves it. Reasoning logs capture the orchestrator's full chain of thought at every step. Attack chains lay out the reproducible path: not "we observed exposed PII," but "here is exactly how user A read user B's order," request by request.
Remediate and re-test: Every finding ships with framework-specific remediation, then flows back to the asset in ASM and becomes a regression test in Escape DAST that runs on every build. We find it once; you stay covered. Trust goes up and time-to-remediation drops, because engineers fix what they can see and argue with what they can't.
And it's built to actually run. No YAML, no test toggles, no templates to maintain. Launching an engagement takes four steps: scope your target URLs, add user accounts (more than one is worth it - a second account typically uncovers 30–50% more issues by unlocking the multi-user testing that finds IDORs and BOLAs), optionally fine-tune context and duration, then review and launch with one click.
Bring what you already have (OpenAPI specs, Postman collections, HAR recordings, Burp exports, additional context, previous pentest reports, ...) and the agents use them to map endpoints and replay real traffic. Point one engagement at multiple assets at once, or skip the UI entirely and launch from your own pipelines through our public API and MCP.
Real-world impact
We recently pointed Cascade at one of our customer’s applications - at the external-facing pricing surface of a consumer platform wçty a web app and the campaign APIs behind it. It found a business-logic flaw no payload-injection scanner would catch: the pricing API accepted a negative quantity for a paid product extra and applied it in server-side calculations, producing negative prices on an unauthenticated, internet-facing endpoint.
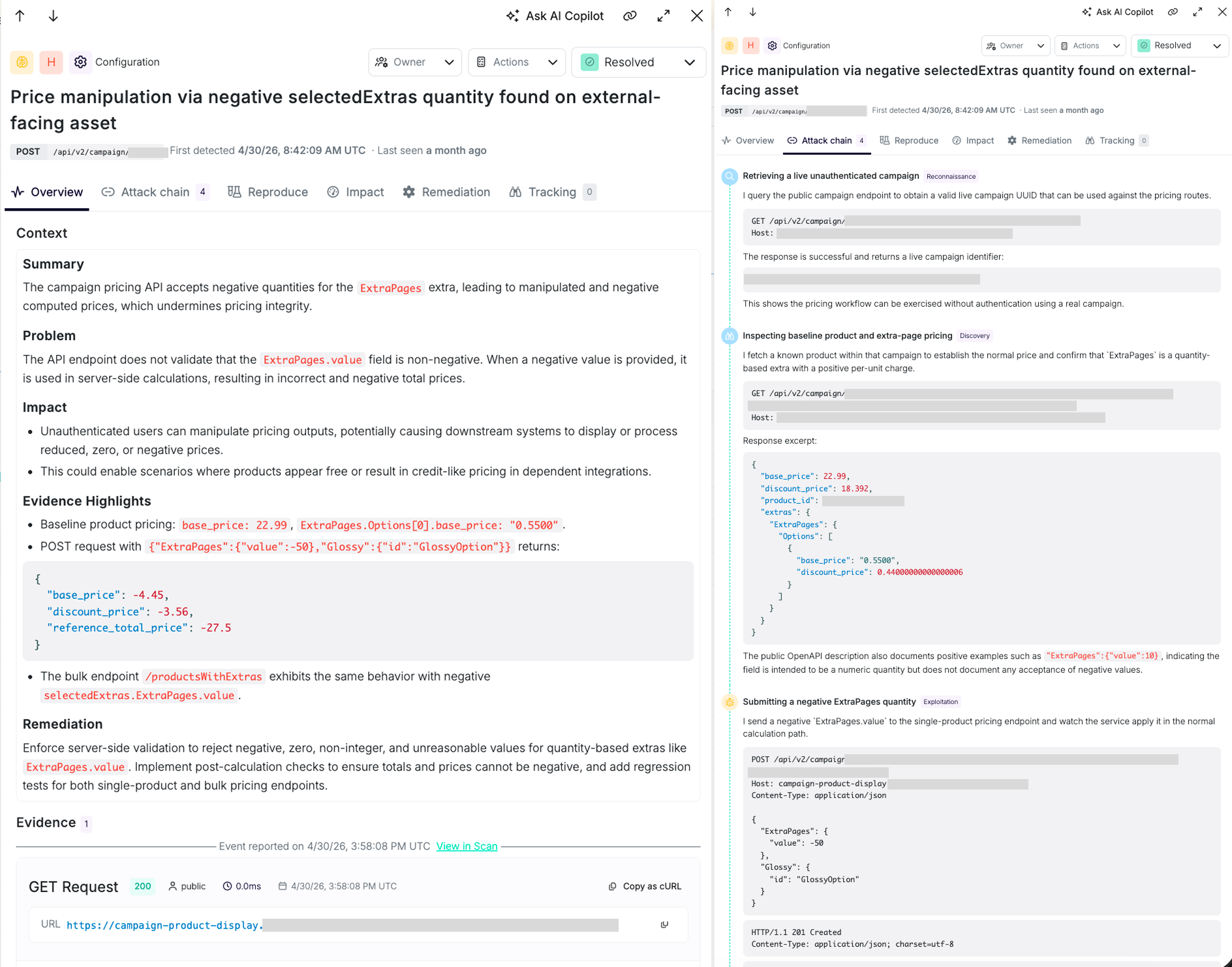
Here's how it reasoned through the attack:
- It pulled a live campaign identifier from a public endpoint, with no authentication, confirming the pricing workflow could be exercised by anyone.
- It fetched a real product to establish the normal price (€22.99) and confirmed that the "extra pages" field was a quantity-based add-on with a positive per-unit charge. The public API docs only ever showed positive examples.
- It submitted a quantity of -50 to the single-product pricing endpoint. The service applied it in the normal calculation path and returned negative totals with a 201 Created.
- It reproduced the same flaw through the bulk pricing route, and then ran a control test: it tried injecting a price field directly. That attempt was rejected ("the key base_price is not a valid extra for this product"). Because arbitrary price fields are rejected while negative quantities are accepted and calculated, Cascade could prove this was a genuine server-side pricing-logic failure.
That control test is the difference between a finding and a false positive. Cascade ruled out the benign explanation, handed over the working exploit and the affected endpoints (single and bulk, and shipped the remediation across three layers: input validation, hardening the pricing function itself, and a final response-layer invariant in a separate tab.
This is the kind of finding that's invisible to traditional scanning and easy to miss even for an experienced pentester. It takes reasoning about how the application is supposed to behave, testing across more than one endpoint, and proving the difference between a real flaw and a reflection. Cascade did all of it in a single engagement.
And this is the kind of feedback that tells us it's working. And another we hear from our design partners on AI pentesting:
"The results from the AI pentesting actually caught something interesting. Even through my own testing, when I was trying to validate how transfers operated, that was something I was running into as well. It's nice to know the scan is recognizing this kind of gap in business logic." — Team Lead, Offensive Security, global payments & fintech platform
How Cascade compares
OWASP Juice Shop
We tested Cascade against OWASP Juice Shop, the industry-standard benchmark for web application security tooling, and compared it directly against Claude Code (running Opus 4.7) used as a raw AI baseline.
Cascade was tested in two modes: black-box (no source code access) and white-box (with source code access). Both are shown below.
AI pentesting benchmark on Juice Shop
| Juice Shop | Cascade (black-box) |
Cascade (white-box) Best result |
Claude Code (black-box) |
Claude Code (white-box) |
|---|---|---|---|---|
| Total | 36 | 49 | 22 | 22 |
| High | 20 | 31 | 11 | 13 |
| Medium | 15 | 17 | 7 | 6 |
| Low | 1 | 1 | 4 | 3 |
Cascade detected 49 vulnerabilities in white-box mode: more than 2x the findings of Claude Code (22). Even in black-box mode, Cascade (36) outperforms Claude Code's best result, demonstrating how purpose-built security tooling outperforms a general-purpose AI on this task.
Real-world applications: Fider & Photoview
Juice Shop is designed to be broken. To benchmark Cascade against more realistic targets, we used two open-source applications – Fider and Photoview – from an independent comparative study published by Doyensec, which assessed multiple AI pentesting solutions on the same targets. We ran Cascade against both apps and benchmarked against the solutions evaluated in that report and again Claude Code.
Note on severity: the solutions compared do not share a unified definition of "critical". For consistency, critical and high findings have been merged.
AI pentesting benchmark on Fider: Cascade vs. Aikido, Xbow & Claude Code
| Fider | Cascade (black-box) |
Cascade (white-box)Best result |
Aikido (white-box) |
Xbow (white-box) |
Claude Code (white-box) |
|---|---|---|---|---|---|
| Total | 20 | 27 | 17 | 18 | 7 |
| High | 4 | 4 | 3 | 3 | 1 |
| Medium | 11 | 12 | 6 | 7 | 3 |
| Low | 5 | 11 | 8 | 8 | 3 |
AI pentesting benchmark on Photoview: Cascade vs. Aikido, Xbow & Claude Code
| Photoview | Cascade (black-box) |
Cascade(white-box)Best result | Aikido (white-box) |
Xbow (white-box) |
Claude Code (white-box) |
|---|---|---|---|---|---|
| Total | 12 | 28 | 24 | 5 | 7 |
| High | 7 | 7 | 6 | 2 | 2 |
| Medium | 2 | 9 | 9 | 2 | 1 |
| Low | 3 | 12 | 9 | 1 | 4 |
On Fider, Cascade leads across the board in both modes, finding 20-27 total vulnerabilities. On Photoview, Cascade (white-box) tops all solutions with 28 findings.
We’ll provide the complete benchmark in a week. Stay tuned!
Black-box vs. white-box
Cascade supports two testing modes: black-box (no source code access) and white-box (with source code access). We know that this choice matters, because plenty of security teams we work with simply can't hand over source: third-party or vendor code, contractual and IP restrictions, or a security policy that says external testing doesn't get to read the repo. For them, "white-box only" tools are a non-starter.
So how much do you give up by keeping the code private with Cascade? Across the apps we benchmarked, less than you'd expect. On Fider, the gap between black-box and white-box is low (15 vs. 16 HIGH+MEDIUM) with Cascade finding nearly as much without access to code. On Photoview, white-box mode unlocks a significant uplift (12 → 28), reflecting how source code access can reveal deeper, code-path-dependent vulnerabilities in certain application architectures.
The takeaway: black-box Cascade delivers serious depth on its own, which is what most customer environments need it to do. It shows it can be a strong option in environments where source access is restricted: third-party integrations, strict regulatory boundaries, or supplier assessments.
And when you can share source, white-box is there to go deeper. You're not forced to choose between testing realistically and testing thoroughly.
Looking ahead
APIs and web apps are where Cascade starts. We're expanding our exploitation agents’ library on a steady cadence. Each new agent broadens coverage for every engagement, immediately. Alongside that, we're deepening the cross-asset and multi-user reasoning and giving you more visibility into what Cascade understood about your application, so you can feed it better context over time. The direction is consistent: more of the work that used to require a human offensive security team, run continuously, with the proof attached.
Get started
Every other AI pentester is sold as a transaction: buy a test, get a report, start over next time. Cascade is the only one built to be part of a program. It is context-aware because it sits next to ASM, compounding because it remembers your business, and continuous because every finding it proves becomes a test within DAST that runs on the next release.
That's the bet we're making: offensive security shouldn't be something you purchase once and file away. It should be a capability that lives inside your platform and gets sharper every time it runs.
See it work against your own attack surface.