GraphQL Wordlist: Free Open Source for Penetration Testing


In cybersecurity, the old saying that the "best defense is a good offense" rings true. This philosophy is reflected in the approach we call offensive security. It involves actively seeking out system vulnerabilities to fix them before they can be exploited. It's about taking the initiative, keeping a step ahead of potential threats, and changing how we approach cybersecurity.
TL;DR: We built the open source GraphQL wordlist for penetration testing based on 60k+ production GraphQL endpoints. It is available on GitHub, and you can access it by visiting this repository.
Wordlists for GraphQL security
The value of wordlists in security
One essential tool in this proactive defense strategy? Wordlists. At their core, wordlists are databases of commonly-used strings: usernames, passwords, URLs; you name it. They're invaluable for various offensive security measures like password cracking or brute force attacks. In the hunt for vulnerabilities, a well-crafted wordlist can be the difference between discovering a weak point and leaving it exposed.
Smart brute force: queries, mutations & arguments
While classic wordlists (such as top X English words) can do the job to brute-force GraphQL, it's far from optimal. We need something... smarter. That's where smart brute force comes in. Instead of blindly guessing at queries, mutations, and arguments with random words, we can extract GraphQL schemas (via the introspection query) and analyze them to extract common recurrent words. Having such a wordlist will drastically increase the performance of brute-force attacks on operations or argument names in terms of precision and speed, as the list size will be way smaller and the words more likely to match the fields.
Why would you need to brute-force arguments and operations in the first place?
At this point, you might be wondering why brute-forcing operations (query or mutation) or argument names would ever be necessary. This is a legitimate interrogation. Generally, brute-force attacks will target the argument content (say, a password sent to the APi), not the field name. But when the schema of a GraphQL API is not accessible (introspection closed, for instance), the first step of any attack is to retrieve it. Using such a wordlist, it is now easy to see how we can reconstruct the said schema by brute-forcing through it. Paired with field suggestions, most schemas can be completely recovered.
Improving our secret weapons: Goctopus & Clairvoyance
Our team at Escape has developed and contributed to two powerful tools for this purpose: Goctopus and Clairvoyance.
Goctopus is our open source reconnaissance tool, allowing us to discover and fingerprint GraphQL APIs in the wild.
Clairvoyance is a tool Escape contributed to that leverages field suggestion and brute force to reconstruct a GraphQL schema.
Both are state-of-the-art GraphQL offensive security tools, and we built this wordlist to improve their performance.
Building our wordlist: a journey of finding, collecting, and parsing 60,000+ GraphQL schemas
GraphQL API hunting with Goctopus
To have a lot of words, we need a lot of schemas. To have a lot of schemas, we need a ton of GraphQL APIs. Hence, our journey began in the wide-open seas of the internet with our trusty open source tool, Goctopus. Scaled across multiple machines (using Kubernetes), it allowed us to discover more than 60,000 GraphQL APIs with an open introspection (accessible schema).
Collecting introspection data
Once we had a list of endpoints, we needed to download all their introspections. This is perhaps the easier step, just a pinch of bash magic and it was done:
INTROSPECTION_QUERY="query IntrospectionQuery{__schema{queryType{name}mutationType{name}subscriptionType{name}types{...FullType}directives{name description locations args{...InputValue}}}}fragment FullType on __Type{kind name description fields(includeDeprecated:true){name description args{...InputValue}type{...TypeRef}isDeprecated deprecationReason}inputFields{...InputValue}interfaces{...TypeRef}enumValues(includeDeprecated:true){name description isDeprecated deprecationReason}possibleTypes{...TypeRef}}fragment InputValue on __InputValue{name description type{...TypeRef}defaultValue}fragment TypeRef on __Type{kind name ofType{kind name ofType{kind name ofType{kind name ofType{kind name ofType{kind name ofType{kind name ofType{kind name}}}}}}}}"
MAX_JOBS=40
total=$(jq length urls.json)
mkdir introspections
current=1
for url in $(cat urls.json | jq -r '.[].url'); do
while [ "$(jobs | wc -l)" -gt "$MAX_JOBS" ]; do sleep 1; done
echo "($current/$total) Fetching introspection for $url"
filename=$(echo $url | sed 's/https:\/\///g' | sed 's/\//_/g')
test -f introspections/$filename.json && echo "introspection for $url already exists" && continue
curl -s -X POST -H "Content-Type: application/json" --data "{\"query\": \"$INTROSPECTION_QUERY\"}" $url | jq . > introspections/$filename.json &
echo "saving to introspections/$filename.json"
current=$((current+1))
done
echo "Deleting empty introspections"
find introspections -type f -empty -delete
echo "Got $(find introspections -type f | wc -l) introspections from $total urls"After a few hours, the script was done, and we were left with more than 70GB of introspection response files.
Parsing the loot: from introspection to CSVs
The last step of our journey is to parse those files to gather the statistics we're interested in.
Rather than just listing the frequency of each word in the schema, we counted them by categories to craft a complete dataset:

After finalizing the design, we had only to write a simple script to parse all this data and let it run.
The wordlist: open source for the greater good
At Escape, we believe that open source matters. We know we're all stronger when we work together and share knowledge. That's why we're making our wordlist - created from over 60,000 GraphQL schemas - available to everyone. It's over on our GitHub repository right now.
In addition to the wordlist, you'll find statistics about the most used words per category. These resources provide a peek into the patterns and trends in GraphQL API design.
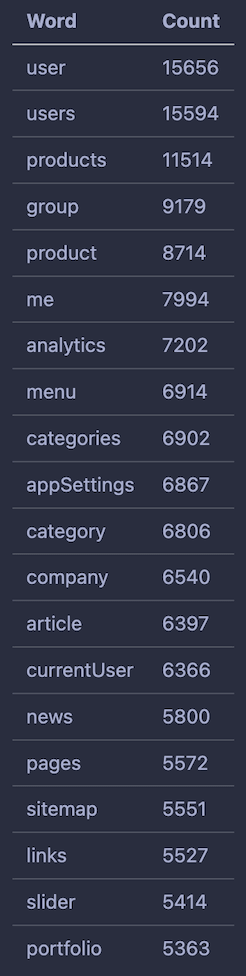
For example, take a look at the Top 20 most used words for query field names. You can see that “user” & “users” are by far the most used query names. Many of those seem predictable, but it's surprising that "portfolio" is Top 20.
Whether you're a security researcher seeking to identify vulnerabilities, or a developer looking to strengthen your GraphQL API, we believe these resources will help.
If you also need an automated solution for GraphQL API discovery and testing, take a look at Escape’s app. It also offers business-centric risk assessments to AppSec teams and shifts security left by assisting developers with remediation.
💡 Want to learn more about GraphQL APIs security? Take a look at our articles below: