Webinar Recap: Building your Product Security Roadmap
In-depth recap of our hands-on product security webinar with James Berthoty—gather the best knowledge and insights!


As we approach the end of the year, many organizations are in the process of building their product security program for 2024. However, building a comprehensive security roadmap can be a daunting task. Last week Escape's CEO, Tristan Kalos, hosted Product Security expert James Berthoty for a webinar titled “ Building Your Product Security Roadmap” to address this topic.
Here’s the video if you’d like to watch the full webinar on YouTube:
Webinar: Building Your Product Security Roadmap available on YouTube
In this article (it's more than 3000 words, so be ready!), we will cover the essential steps we went through during the webinar. These steps are crucial to consider when building your product security roadmap. Additionally, we will discuss best practices for effectively securing your applications and aligning your security roadmap with industry standards. Before concluding with the Q&A section, we will touch on incident response and how to prepare for unexpected security threats.
Building product security roadmap: The foundations
At first, we covered the foundational steps you need to consider before building your product security roadmap. You can find the recap in the table below:
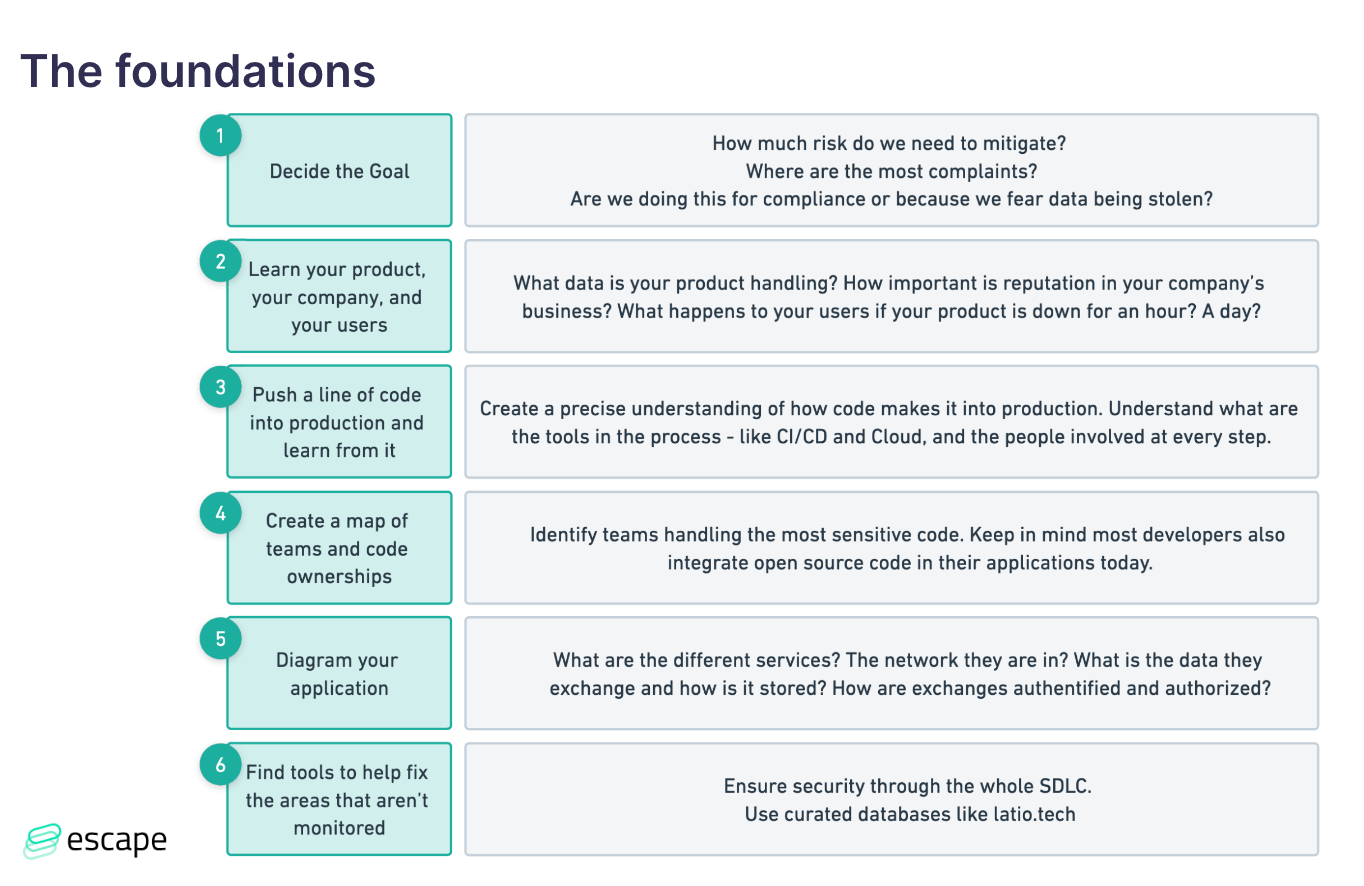
Setting goals and understanding risks
Before diving into the product security roadmap itself, it's crucial to define your goals and understand the risks your organization faces. Ask yourself why you're building a product security roadmap. Are you doing it for compliance purposes, to protect against data breaches, or to ensure uninterrupted service? Understanding your objectives will help you prioritize your security efforts.
"Step one from these goals is the most important: how much risk do we need to mitigate? And are we doing this for compliance? Back when I did a lot of SOC 2 automation consulting, we would be usually about halfway through the sales process where the team would understand, what the scope of a SOC 2 audit was and figure out - are we doing this because we just want to get a successful SOC 2 audit piece of paper or on the other end because we need to close this deal in a hurry? In which case, this list that you're seeing gets narrowed down to three things across all of it because you're just trying to check the box to go as quickly as possible to get SOC 2 completed."
Learning and understanding your product, company, and users
To create an effective security strategy, you must become an expert in your product, company, and users. Understand the data your product handles, the importance of your company's reputation, and the impact of any downtime on your users. This knowledge will help you identify the weak spots and potential threats to your product.
Understanding the development process
To secure your applications, you need to understand the entire development process. From the moment a developer writes a line of code to the code running in production, you must be aware of every step and the tools used along the way. This includes mapping out different teams and their code ownership, as well as understanding data flows and storage in your product.
Identifying security gaps and tools
Once you have a clear understanding of your product and development process, it's time to identify any security gaps. Determine what tools you already have in place and assess whether they cover all your security needs. If there are gaps, find the right tool to address them. Remember, onboarding new tools should be a thoughtful decision that aligns with your security strategy.

Risk assessment
"A lot of CISOs want to prioritize their security program based on risk mitigation. And what can be challenging about this is that a lot of engineers don't have a realistic idea of where the risk actually is because they're too in the weeds of, like, 'I know that this secret isn't handled properly in this particular application context. And I've been wanting to redo it or our firewalls need an overhaul, or we need to switch to this tool.' They're all very focused on the weeds things."
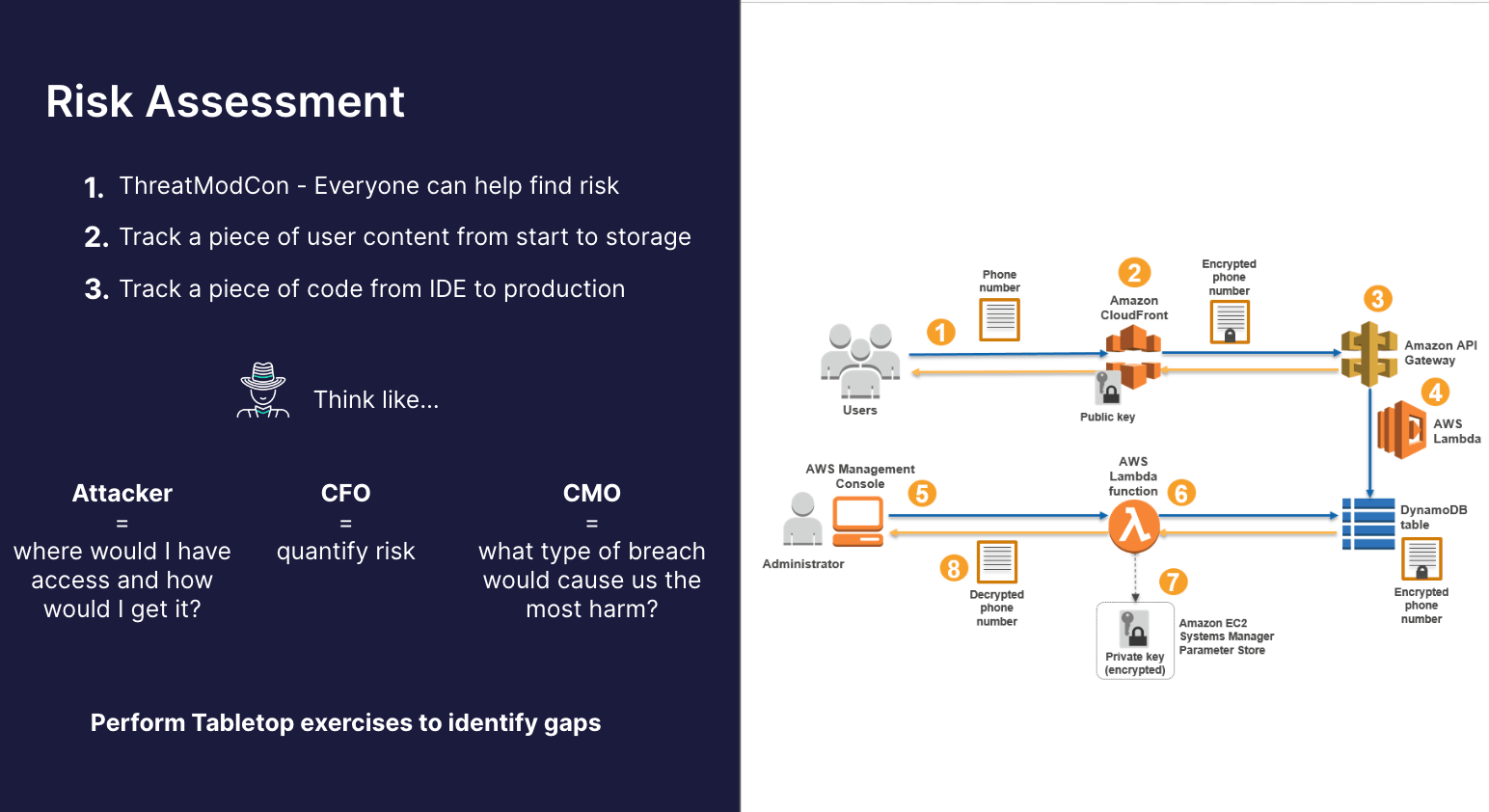
During the webinar, we went through key takeaways from a recent threat modeling conference, emphasizing that everyone can contribute to identifying risks. While threat modeling is often associated with experienced application security experts, real-world breaches frequently occur through simple, low-level processes, such as a DevOps engineer's compromised personal computer or an application key leak to a GitHub repository. We want to highlight the importance of involving various teams, including customer support and the help desk, in the risk assessment process.
It is recommended to create meaningful diagrams focusing on the application layer and tracing code from IDE to production to pinpoint vulnerabilities effectively.
It is important to think like an attacker, align with executive priorities, and perform tabletop exercises with cross-functional teams to reveal gaps and develop effective incident response plans.
"If someone were to gain access to our application's runtime context through a supply chain attack, what actions could they take with a reverse shell on a pod resulting from a supply chain takeover? And then, start working with the DevOps team. Usually, all you have to do is run a print on a pod and it's like way over permission. And then you've just started your roadmap, right? Or we need to identify supply chain stuff. We need to create an incident response plan, we need to limit pod-to-pod permission. How can we further enhance runtime protection? There is a million different things that a tabletop will reveal if you actually take the step to involve those teams instead of just like theorizing it or keeping it like purely executive-driven."
And in the end, you should strive for a balanced approach by considering the actual risk your business faces.
"You're trying to balance the speed of deployment with the amount of security. It's not your job to always be the maximal security guy."
Compliance frameworks and standards
Compliance frameworks, such as SOC 2, ISO 27,001, HIPAA, and PCI, play a significant role in shaping security roadmaps.
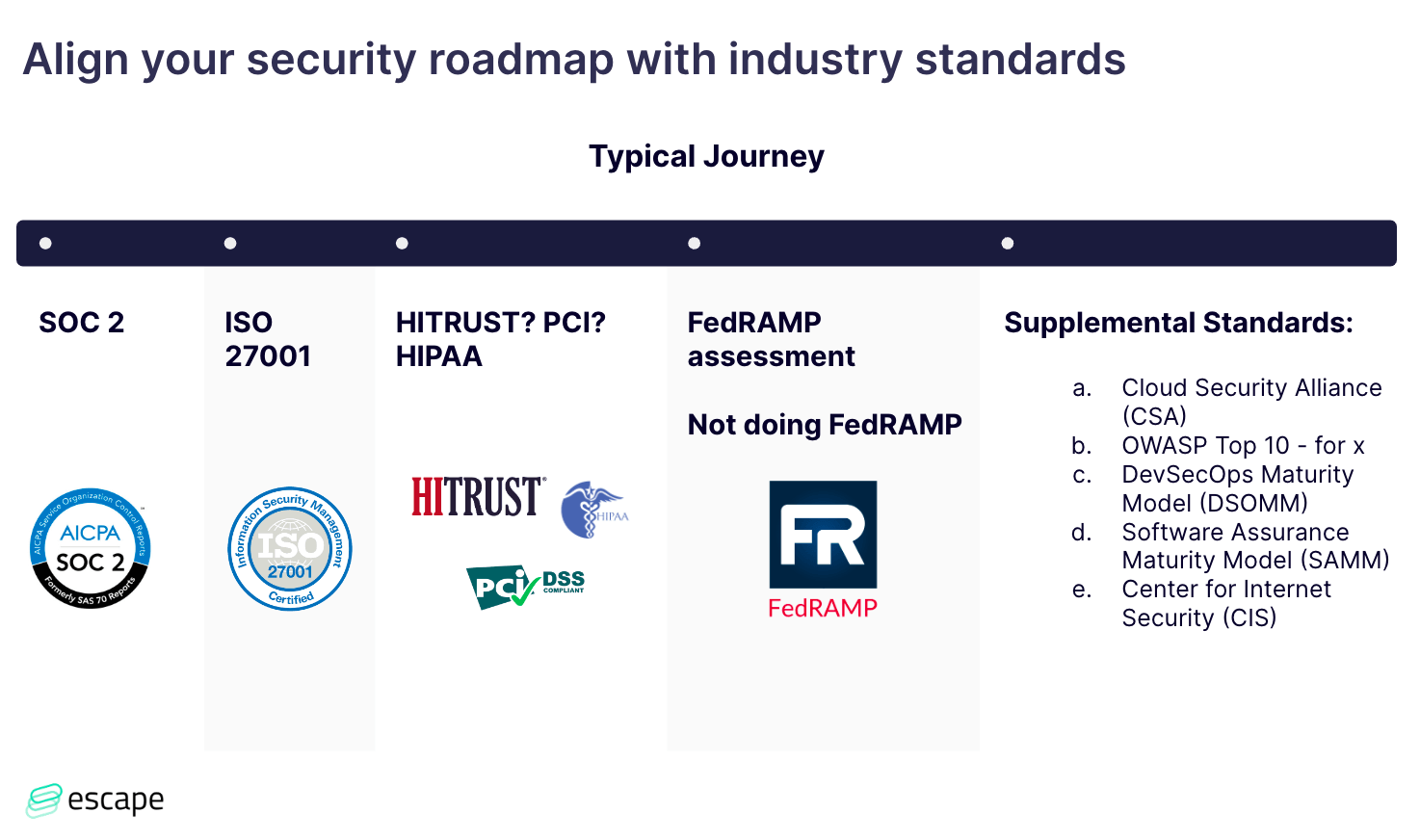
Starting with SOC 2, which is especially crucial for startups engaging with large enterprises, we emphasize the significance of viewing compliance as an outcome rather than a standalone goal.
"I view compliance as an outcome of security, not as the goal of security. And so what I mean by that is that if you're doing everything really well that you should be doing from a security standpoint, the compliance should boil down to creating a couple of paper policies, not some giant technical hurdle that's gonna take years and years to do."
SOC 2 audits focus on our adherence to internal security policies, providing an opportunity to define our security posture comprehensively.
As the journey progresses to ISO 27001, we stress the international nature of this standard and its alignment with a robust SOC 2 foundation (if you've done a good job with SOC2, ISO 27001 should be easy). The major thing to keep in mind, that people don't expect, is that a part of an ISO 27001 audit is an on-site visit and looking at things like your server closet, your network configuration in your offices - your physical security stuff.
Navigating through compliance standards like HIPAA and PCI, we highlight the complexities involved and the need for strategic considerations - you should ask yourself whether it's really required for your organization or if you can find a workaround. PCI is tempting to do and really all PCI is complicated because it's very much focused on the network controls and the data encryption controls around cardholder data specifically. James wouldn't recommend it as just a general security practice because it is very much focused on cardholder data and how you're protecting it.
Depending on the maturity of the company, FedRAMP, identified as a gold standard, is acknowledged for its meticulous and granular audit requirements, setting it apart in terms of rigor, but it is often just too much for organizations.
Our advice centers around starting with SOC 2 as a foundational step, not only enhancing security but also streamlining business interactions by addressing common inquiries from clients. The approach involves scaling up based on business needs and aligning with recognized industry benchmarks. From there, you can scale up on what makes sense.
If you're looking for supplemental standards, don't hesitate to check out the last column in the table above.
"And the main power I found in doing this is that it's sort of like this secret power of unlocking funding for whatever tool that you're going after or that you want to add. If you, as an organization, have committed to follow the Cloud Security Alliance guidelines or to follow the DevSecOps Maturity Model or to prioritize the OWASP TOP 10. Quarter after quarter, show how you've grown in each of the different areas."
Incident response and runtime security
Incident response is a critical aspect of any security roadmap. It's important to have a clear plan in place to handle security incidents effectively.
"With incident response, it's all about just driving that consistent growth across all of your teams and working with them to build a meaningful response process."
There are so many tools out there right now in a cloud context that focus on configuration scanning and vulnerability management. In the industry that is definitely where the emphasis has gone, especially with shift-left ideology and the importance of fixing misconfigurations early. But it's important that you actually know: How am I going to actually respond to an incident that gets detected and where do I actually have coverage of my runtime protection?
During the webinar, James emphasized that there is a hard distinction between configuration scanning and runtime alerting. A configuration scanning alert is going to go to a developer or DevOps person to fix the misconfiguration. Whereas a runtime alert is something that a security person can actually do something about.
"That's why I think it's important to emphasize the incident response aspect of what your actual coverage looks like. And this can be really hard to do granularly and tie to a roadmap because a lot of times people will buy one endpoint provider, and think that it's covering all their bases. So they'll really overlook. Do we actually have enough container contacts to discover what's happened? "
Runtime security, such as runtime application self-protection (RASP), is also crucial for identifying and mitigating threats at the application level. It is the "gold star of security" - an extremely advanced approach, involving collaboration with developers on log data or proactive security integration into applications.
If you observe instances where the system is initiating SQL injection attempts or verifying user passwords against known databases of compromised passwords, it signifies potentially malicious activities. These additional actions, such as attempting authentication without Multi-Factor Authentication (MFA), fall into the category of alerts that require collaboration with developers. It's crucial to consider these potential security threats initiated by users. Making these alerts actionable is vital, as often, alerts are generated but directed to security analysts who might lack the capability to address them effectively. So it's important that you're building as much as you can programmatic responses to these situations.
"Can we kill the user session? Should we force a password reset? Can we block an IP on the fly? If it goes into a honeypot or something. These are pretty advanced application level responses that you can build into your roadmap as really cool projects to work with developers on."
And at the end of the conversation, we're turning towards SIEM (Security Information and Event Management). When considering the adoption of SIEM solution, it's crucial to acknowledge how the application and cloud security tools evolved. With advancements in these domains, certain tools can mitigate the immediate necessity for SIEM by focusing on cloud trail and workload logs, incorporating technologies like EBPF in cloud trail analysis, and examining configuration data within the CI/CD pipeline.
However, as your security needs mature, especially for more advanced capabilities, SIEM becomes instrumental for building custom rules and correlations. It's recommended to designate a dedicated individual or team to consistently manage and refine a list of detections within your environment. While this can be monotonous work, it remains highly important. Regular engagement with stakeholders, including meetings with developers to discuss potential exploits, detection strategies, and response protocols, are vital. These discussions won't happen organically, so you must ensure a proactive security stance.
Wrapping up
Building a product security roadmap requires careful planning and a deep understanding of your organization's unique needs. By setting clear goals, understanding risks, and aligning with industry standards, you can create a roadmap that effectively secures your applications. Remember, security is an ongoing process, and it's important to continuously assess and improve your security strategy.
As a reminder, you can view the full webinar on YouTube.
If you're looking for tools to enhance your security efforts, check out Latio.tech website for a curated list of recommended tools. And if you want to learn more about application security or API security, visit our blog.
Q&A
During the webinar session, James addressed a couple of questions and remarks from the viewers, you can find the recap below. For more detailed answers, feel free to get back to the webinar video!
Do you consider maturity models as a framework to implement as it is or use them as a north star for your security programs?
I view frameworks as a South Star if that makes sense. I always view the frameworks as lagging behind actual security by their own nature. Some security thing gets discovered and then people talk about it and then they implement it and then it gets included in the audit standards. I view it as the bare minimum bar of - let's make sure we're doing all of this stuff. And then we can actually excel in security after we've done that. The reason I wouldn't use it as a North Star is because I think, what I just said, applies to SOC 2 and ISO and maybe even CSA but it doesn't apply to, for example, CIS, which you definitely could use as a North Star. The problem with doing that is it's just so granular that you're setting an impossible standard. And I don't necessarily think that's super helpful either. So all that to say it really depends on the standard, but in general, I treat compliance frameworks as the bare minimum of what we should be doing and then anything else is bonus security stuff.
Let me give an actual example too. Consider the malware signature-based scanning requirement in SOC 2. While that's certainly a good thing to do, it falls short compared to an EDR (Endpoint Detection and Response) platform. EDR might not be a compliance requirement now, but it represents a superior security approach. And so that's what I mean by it's a lagging indicator. Too many companies don't have any malware detection and absolutely, if you don't have any, you should do it. But really the North Star is like implementing any of the EDR, cloud EDR providers.
First of all, on your Windows servers if you have them, but then going into the container space - the Kubernetes space. Kubernetes EDR is not going to be a compliance requirement for 5 to 10 years. On the shallow end it's me guessing at that.
But it's the best security you could have and it's not gonna show up on any of these frameworks because it's expensive and hard to implement. The technical skill sets aren't there for a lot of organizations. And so that's sort of where I'm coming from as far as it's a good North Star if you don't have anything, but it's not the actual thing that you want.
And there are other ways to check that box, that's what I'm saying because the danger you could run into is thinking like - SOC 2 says we need a malware scanner, we need to buy a malware scanner. But really, you should buy an EDR provider that you can also say is a malware scanner because they also do that. And so that's just sort of, you know, we're being careful in terms of how are we meeting these things.
What SAST and DAST tools would you recommend?
If you go to the list.latio.tech, you can get all of my thoughts on DAST and SAST stuff. Obviously, I can recommend Escape for DAST stuff.
They're an easy recommendation but the thing with DAST is it's become very popular to say that DAST is dead or something. That's just because 90% of DAST tools are legacy and suck. So I won't name them all here, just to keep myself out of trouble. But there are plenty of awful DAST tools that crawl your app, miss a bunch of stuff, and take hours to run.
There are only a couple of examples of tools that can run in the pipeline on just your API data, read the API documentation, and fuzz those endpoints directly and that's the value of the DAST tool to look for.
There are a million recommendations on that site that I won't go into, but they have the same problem, right? Like the biggest legacy players in SAST and DAST both like, can't run in the pipeline, they take hours to run, and the UI sucks. You're drowning in alerts.
Like they just totally don't understand how modern applications get built and deployed.
And so that's where I think that this market in particular is really valuable to look at startups um or smaller companies as opposed to the giant legacy players.
Dashboards provide visibility to leadership and help us to plan which vulnerabilities to prioritize effectively.
I emphasize all the time that fixing vulnerabilities is the priority over dashboarding them. And you know, as someone, who also has to get executive buy-in, I totally understand that your CISO really just wants to know who they have to go yell at. What's the fundamental outcome that we're going for? And if the outcome is 'I'm a security engineer, and I like my job, and I want to keep it by making dashboards for my leadership,' then the CISO is using a hammer all the time to say, for example, why does the infrastructure team have 10,000 vulnerabilities? And it's only gone up month over month.
That relationship that you have with that team is fundamentally broken because they're just going to endlessly get this workstream from security that they're going to complain about and say it's totally out of touch. It doesn't make any sense. We have all these bombs because we have these servers that can't get fixed and it doesn't matter anyway because they're not even accessible.
The network, and these fixes - they don't actually matter because we're going to decommission that service anyway. We've been wanting to fix this forever with getting a network change and they have their own plans that all of this picture of the vulnerabilities they have goes into.
So what I'm trying to emphasize is that the conversations with those teams should be based around the vulnerabilities that we're looking at. How are we gonna go about fixing them? Instead of this workflow of surfacing the leadership reports which then come down as hammers from above to everyone else.
Let me use an example to highlight a common challenge in handling Linux vulnerabilities. If I approach it without considering how I'd practically guide a developer, I might end up creating 5000 tickets for every CVE. For instance, asking a developer to upgrade a group of servers or a Golden AMI through a single ticket is straightforward and manageable for them in a day or so. On the contrary, issuing 5000 tickets, especially screaming about how this CVE is 10 out of 10 that we need to fix immediately and drop everything, can lead to chaos. Developers, thinking it's a critical and urgent fix, might SSH into each Linux box individually, spending an entire week on upgrading a single package or applying mitigation. When all they really had to do was run an app to upgrade and redeploy their golden image. So that's all I mean, is if, us, security can provide the context based on how they're going to actually fix it instead of based on "here's the CVE we're seeing and why we're freaking out about it", it can just help make the whole process go more smoothly and ultimately faster.
So it's not that I think the dashboards are useless like executive buy-in is key for getting all of this stuff done. It's just that ultimately staying focused on the outcome is working with the developer to fix an issue as opposed to the outcome getting that team in trouble from the executive.